6.3 Basic Distributed Data Structures
Linda’s tuple space is a type of “set” that can hold duplicate elements, also known as a bag or multiset. Tuplespace can, however, be used to implement data structures other than bags by adjusting the structure of tuples and tuple operations.
How to Write Parallel Programs: A First Course [CG90][10] describes various distributed data structures that can be implemented with tuple space. The three main categories described are as follows:
- Bag
-
Data structures whose elements can be identified only by their value
- Struct, hash
-
Data structures whose elements can be identified by name
- Array, stream
-
Data structures whose elements can be identified by position
The following sections explain these basic distributed data structures. These basic structures contain lots of hints for using TupleSpace.
Expressing the Bag Data Structure
A bag is a variation of a set and allows duplicate elements. Like a set, its elements are unordered. This is the most natural way to use TupleSpace. A bag has two operations: addition and deletion of an element. In TupleSpace, they are equivalent to write and take.
This is an example of adding an element:
$ts.write(['fact', 1, 5]) |
And this is an example of deleting an element:
$ts.take(['fact', Integer, Integer]) |
Combining write and take enables you to manage tasks among multiple servers, as described in Figure 33, Expressing the factorial request tuple and the result tuple as a service.
Here’s an example:
$ts.write(['fact', 1, 1000]) |
|
$ts.write(['fact', 1001, 2000]) |
|
$ts.write(['fact', 2001, 3000]) |
|
|
|
.... |
|
|
|
$ts.take(['fact-answer', 1, 1000, nil]) |
|
$ts.take(['fact-answer', 1001, 2000, nil]) |
|
$ts.take(['fact-answer', 2001, 3000, nil]) |
|
|
|
.... |
As an example of bag usage, let’s implement a semaphore class called Sem (see Figure 36, The implementation of a semaphore using TupleSpace). In a semaphore, there are two operations: down and up. down takes a resource, and up releases the resource. If you think of a tuple in TupleSpace as a resource, you can express a semaphore by writing and taking a tuple. Counting semaphores (there are n number of resources in semaphores) can also be expressed using n number of tuples.
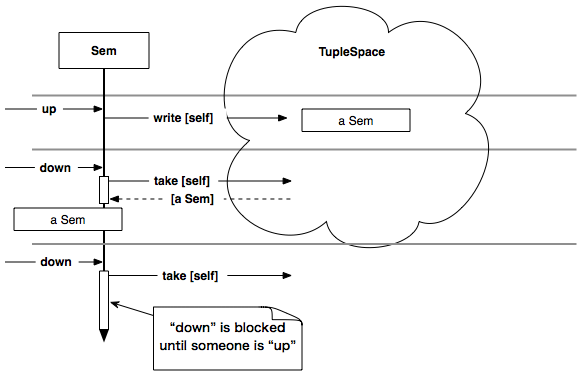
Figure 36. The implementation of a semaphore using
TupleSpace.
The down method is equivalent to write, and the up method is equivalent to take.
| sem.rb | |
class Sem |
|
include DRbUndumped |
|
|
|
def initialize(ts, n, name=nil) |
|
@ts = ts |
|
@name = name || self |
|
n.times { up } |
|
end |
|
|
|
attr_reader :name |
|
def synchronize |
|
succ = down |
|
yield |
|
ensure |
|
up if succ |
|
end |
|
|
|
private |
|
def up |
|
@ts.write(key) |
|
end |
|
|
|
def down |
|
@ts.take(key) |
|
return true |
|
end |
|
|
|
def key |
|
[@name] |
|
end |
|
end |
|
Here is a simple usage example of Sem:
require './sem' |
|
require 'rinda/tuplespace' |
|
sem = Sem.new(Rinda::TupleSpace.new, 1) |
|
sem.synchronize do |
|
.... |
|
end |
key is a method to generate a tuple for each Sem object, and it returns a tuple that only contains @name as an element.
[@name] |
Anyone can specify @name, but the value has to be unique within a system. The default is set to Sem itself to guarantee consistency. If @ts tuplespace and Sem share the same process, then the instance of Sem is included within a tuple. If the @ts tuplespace is a remote object, then DRbObject becomes an element to refer to the Sem instance.
The tuplespace implementation of a semaphore is less convenient than SemQ because it requires a tuplespace to be supplied to the constructor. (If we just want the properties of a semaphore, the Queue implementation is preferable to the tuplespace implementation.)
| semq.rb | |
require 'thread' |
|
class SemQ |
|
def initialize(n) |
|
@queue = Queue.new |
|
n.times { up } |
|
end |
|
|
|
def synchronize |
|
succ = down |
|
yield |
|
up if succ |
|
end |
|
|
|
private |
|
def up |
|
@queue.push(true) |
|
end |
|
def down |
|
@queue.pop |
|
end |
|
end |
|
The TupleSpace version has more lines than the Queue version because it has to prepare TupleSpace. If you want to use it only as a queue, Queue may suit you better.
Structs and Hashes
Structs and hashes are structures with a key and a value. This is similar to Struct and Hash in Ruby.
The basic structure is to use a tuple with a key and a value as a pair.
[key, value]
The following is an example of initializing a guid field with a 0 value:
ts.write(['guid', 0]) |
To update the value, use take and write.
key, value = ts.take(['guid', nil]) |
|
ts.write(['guid', name + 1]) |
The key part doesn’t have to be one element of a tuple. You can use multiple elements as a key. An example is expressing an attribute of an object.
[object, attr_name, value]
The preceding example shows that you can use the combination of the object and the attribute name as a key.
In Ruby, you can define a struct with Struct.new.
>> S = Struct.new(:foo, :bar) |
|
>> s = S.new(1, 'bar') |
|
>> s.foo = s.foo + 1 |
|
>> s.foo |
|
=> 2 |
And the equivalent with TupleSpace is as follows:
>> s = Object.new |
|
>> ts = Rinda::TupleSpace.new |
|
>> ts.write([s, 'foo', 1]) |
|
>> ts.write([s, 'bar', 'bar']) |
|
>> tuple = ts.take([s, 'foo',nil]) |
|
>> ts.write([s, 'foo', tuple[2] + 1]) |
To perform an update, it is important to perform a take before the write. The take operation is effectively an exclusive lock on the value, preventing other processes from changing the value during the update operation.
As a next example, let’s implement a “barrier synchronization” mechanism using this data structure.
Consider a program with multiple processes or threads running in parallel. Barrier synchronization is a mechanism that prevents the program from starting phase n+1 until after all processes have completed phase n.
You can implement a barrier using a [key, n] tuple, where key is the barrier name and n is the number of processes to wait for. To initialize the barrier, all you do is write the [key, n] tuple into tuplespace.
Consider a program with multiple processes or threads running in parallel. Barrier synchronization is a mechanism that prevents the program from starting phase n+1 until after all processes have completed phase n.
| barrier.rb | |
class Barrier |
|
def initialize(ts, n, name=nil) |
|
@ts = ts |
|
@name = name || self |
|
@ts.write([key, n]) |
|
end |
|
def key |
|
@name |
|
end |
|
end |
|
When a process reaches a barrier, it performs a take on [key, nil], decrements the value, and writes the result to tuplespace. It then performs a read on [key, 0], which will block until the number of processes to wait for becomes 0. When all n processes reach the barrier, [key, 0] gets written, and all of the waiting read operations are unblocked. That all the processes can synchronize their wait just by reading [key, 0] is one of the coolest things about tuplespace.
| barrier_sync.rb | |
class Barrier |
|
def sync |
|
tmp, val = @ts.take([key, nil]) |
|
@ts.write([key, val - 1]) |
|
@ts.read([key, 0]) |
|
end |
|
end |
|
You may wonder how you can achieve an atomic operation without using any exclusive locking mechanism such as the Mutex#synchronize method. Now that the barrier tuple is temporarily removed from tuplespace by take([key, nil]), no other processes can take the tuple until you do write([key, val-1]). You can modify the value safely while take([key, nil]) operations from other processes are being blocked. This technique is very handy.
Last, let’s abstract this process into methods without worrying too much about its practicality. Approach it as if you were solving a puzzle.
| tsstruct.rb | |
class TSStruct |
|
def initialize(ts, name, struct=nil) |
|
@ts = ts |
|
@name = name || self |
|
return unless struct |
|
struct.each_pair do |key, value| |
|
@ts.write([@name, key, value]) |
|
end |
|
end |
|
attr_reader :name |
|
def [](key) |
|
tuple = @ts.read([name, key, nil]) |
|
tuple[2] |
|
end |
|
def []=(key, value) |
|
replace(key) { |old_value| value } |
|
end |
|
def replace(key) |
|
tuple = @ts.take([name, key, nil]) |
|
tuple[2] = yield(tuple[2]) |
|
ensure @ts.write(tuple) if tuple |
|
end |
|
end |
|
This class takes the tuplespace, assigns an object identifier, and then writes a struct into the tuplespace during its initialization.
One nonpractical point about this TSStruct is that you can replace only an existing element, but you can’t add a new element once instantiated.
Arrays and Streams
Arrays and streams contain order and position information. You can define them by making a tuple with index and value. This structure includes set structures such as matrixes, arrays, and streams.
Arrays, Matrixes, and Basic Streams
Each element is either a tuple of index and value...
[index, value] |
or a tuple with object, index, and value.
[object, index, value] |
A 2x2 matrix of an object a can be expressed as follows:
['a', 0, 0, 1.0] |
|
['a', 1, 0, 0.0] |
|
['a', 0, 1, 0.0] |
|
['a', 1, 1, 1.0] |
Even though you can express a matrix as in the preceding example, it may cause interprocess communication overhead if you leave this in tuplespace or if it requires synchronization between threads.
If you want to use Queue where only one process can append a value and only one process can push out a value, you can express it as an array with an index and a value.
['stream', 1, value1] |
|
['stream', 2, value2] |
|
['stream', 3, value3] |
|
.... |
If you let a writing object manage @tail index information, then multiple writing objects can’t append the same stream.
| stream.rb | |
class Stream |
|
def initialize(ts, name) |
|
@ts = ts |
|
@name = name |
|
@tail = 0 |
|
end |
|
attr_reader :name |
|
def push(value) |
|
@ts.write([name, @tail, value]) |
|
@tail += 1 |
|
end |
|
end |
|
The best way to let multiple processes append is to let the tuplespace manage the tailing index information. Do you remember the struct and hash data structures from Structs and Hashes? You can create a tuple that consists of a name and its tail value as follows:
['stream', 'tail', tail index] |
The following is the modified version of the Stream class that lets you append using multiple processes. You need to add more functionality to make this work for production use, but it’s more important to understand the algorithm here.
| stream_2.rb | |
class Stream |
|
def initialize(ts, name) |
|
@ts = ts |
|
@name = name |
|
@ts.write([name, 'tail', 0]) |
|
end |
|
attr_reader :name |
|
def write(value) |
|
tuple = @ts.take([name, 'tail', nil]) |
|
tail = tuple[2] + 1 |
|
@ts.write([name, tail, value]) |
|
@ts.write([name, 'tail', tail]) |
|
end |
|
end |
|
So far, we’ve looked into the array, matrix, and stream data structures. There are some variations for streams, so let’s talk about that next.
RDStream and InStream
There are two variants of streams, differing by the behavior of their read operations. The “in” stream consumes elements as they are read, while the “rd” (read) stream does not consume elements as they are read.
Let’s discuss the “rd” stream first. The “rd” stream doesn’t modify the stream itself. It uses a “read” operation to read out an element, and the position of the head information is managed by the reader object.
| rdstream.rb | |
class RDStream |
|
def initialize(ts, name) |
|
@ts = ts |
|
@name = name |
|
@head = 0 |
|
end |
|
|
|
def read |
|
tuple = @ts.read([@name, @head, nil]) |
|
@head += 1 |
|
return tuple[2] |
|
end |
|
end |
|
The @head instance variable represents the head of the stream for the reader. It reads an element and increments @head by one. When the @head value exceeds the index of the stream, it gets blocked until a new element is added to the stream.
Let’s think about the “in” stream now. The “in” stream deletes each element as it is read from the stream.
If only one process accesses a stream, all you need to do to change from the “rd” stream is to replace @ts.read with @ts.take.
| instream.rb | |
class INStream |
|
def initialize(ts, name) |
|
@ts = ts |
|
@name = name |
|
@head = 0 |
|
end |
|
|
|
def take |
|
tuple = @ts.take([@name, @head, nil]) |
|
@head += 1 |
|
return tuple[2] |
|
end |
|
end |
|
However, this doesn’t work when multiple processes access the same stream. Each process manages @head information separately. Once a process takes out an element from the stream, no other processes can read from the stream.
How do we solve this problem? Do you remember how we managed appending elements to a stream by multiple processes in Arrays, Matrixes, and Basic Streams? Like “tail” information, tuplespace can manage “head” information to share between multiple processes. Let’s add the following tuple to manage @head information:
['stream', 'head', head index] |
The following is the class definition:
| instream_2.rb | |
class INStream |
|
|
|
def initialize(ts, name) |
|
@ts = ts |
|
@name = name |
|
@ts.write([@name, 'tail', 0]) |
|
@ts.write([@name, 'head', 0]) |
|
end |
|
|
|
def write(value) |
|
tuple = @ts.take([@name, 'tail', nil]) |
|
tail = tuple[2] + 1 |
|
@ts.write([@name, tail, value]) |
|
@ts.write([@name, 'tail', tail]) |
|
end |
|
|
|
def take |
|
tuple = @ts.take([@name, 'head', nil]) |
|
head = tuple[2] |
|
tuple = @ts.take([@name, head, nil]) |
|
@ts.write([@name, 'head', head + 1]) |
|
end |
|
end |
|
You may have realized by now that INStream functionality is actually the same as the Queue library in Ruby.