10.5 Using RBTree for Range Search
So far, we’ve seen how the crawler and the indexer use the tags and notification functionalities of Drip to update a document into the index. In this section, we’ll look into how this indexing works internally.
The indexer uses a library called RBTree. RBTree provides a binary tree data structure and algorithm suited for a search. It’s an acronym for “red-black tree,” not “ruby-tree.” Ruby’s Hash class uses a magical function called a hash function. The function generates a hash value from a key object so that the value can be searched at a constant speed. RBTree prepares a sorted array (the underlying implementation uses a tree structure but doesn’t provide an API to access the tree directly) and searches a value using binary search. You can do various interesting things using the sorting characteristics.
Let’s try to implement a small indexing dictionary class. It lists the location of each word (equivalent to the page number of a book). You can easily implement this using Hash as follows:
| dripdict1.rb | |
class Dict |
|
def initialize |
|
@hash = Hash.new {|h, k| h[k] = Array.new} |
|
end |
|
|
|
def push(fname, words) |
|
words.each {|w| @hash[w] << fname} |
|
end |
|
|
|
def query(word, &blk) |
|
@hash[word].each(&blk) |
|
end |
|
end |
|
dict = Dict.new |
|
dict.push('lib/drip.rb', ['def', 'Drip']) |
|
dict.push('lib/foo.rb', ['def']) |
|
dict.push('lib/bar.rb', ['def', 'bar', 'Drip']) |
|
dict.query('def') {|x| puts x} |
|
# => ["lib/drip.rb", "lib/foo.rb", "lib/bar.rb"] |
|
Let’s assume that some files are updated so that we have to rebuild the index.
To remove old indexes and add new indexes, you need to iterate over all Arrays inside the Hash. You can work around this problem by replacing the internal Array into Hash. Here’s the revised version with Hash:
| dripdict2.rb | |
class Dict2 |
|
def initialize |
|
@hash = Hash.new {|h, k| h[k] = Hash.new} |
|
end |
|
|
|
def push(fname, words) |
|
words.each {|w| @hash[w][fname] = true} |
|
end |
|
|
|
def query(word) |
|
@hash[word].each {|k, v| yield(k)} |
|
end |
|
end |
|
dict = Dict2.new |
|
dict.push('lib/drip.rb', ['def', 'Drip']) |
|
dict.push('lib/foo.rb', ['def']) |
|
dict.push('lib/bar.rb', ['def', 'bar', 'Drip']) |
|
dict.query('def') {|x| puts x} |
|
# => {"lib/drip.rb"=>true, "lib/foo.rb"=>true, "lib/bar.rb"=>true} |
|
Hmmm, note that the value no longer has meaning. It only contains a value of true. The nested Hash looks almost like a tree structure.
RBTree offers a similar API to Hash, so we can simply replace the preceding Hash with RBTree, but I’ll introduce better ways of dealing with RBTree.
Let’s expand the Hash version. This time, the key is the combination of the word and its location (filename). This is as if we flattened the previous nested Hash tree-like structure.
| dripdict3.rb | |
require 'rbtree' |
|
|
|
class Dict3 |
|
def initialize |
|
@tree = RBTree.new |
|
end |
|
|
|
def push(fname, words) |
|
words.each {|w| @tree[[w, fname]] = true} |
|
end |
|
|
|
| ① | def query(word) |
@tree.bound([word, ''], [word + "\0", '']) {|k, v| yield(k[1])} |
|
end |
|
end |
|
dict = Dict3.new |
|
dict.push('lib/drip.rb', ['def', 'Drip']) |
|
dict.push('lib/foo.rb', ['def']) |
|
dict.push('lib/bar.rb', ['def', 'bar', 'Drip']) |
|
dict.query('def') {|x| puts x} |
|
# => |
|
# "lib/bar.rb" |
|
# "lib/drip.rb" |
|
# "lib/foo.rb" |
|
The query method calls the bound method that looks up elements within the boundaries of two keys. The bound method takes lower and upper as arguments.
You can obtain the index of a word if you specify the minimum and maximum values for the word as keys. The minimum value consists of an array of the word itself and a blank string (for example, [word, ”]). What would the maximum value for the word be then? It’s hard to come up with ideas when thinking this way. Instead, let’s think about “the minimum value of the word that comes right next to the word you are looking for.” Since Ruby’s String can include \0, the maximum value of the word is the word itself plus \0. This looks a bit tricky. ① hides such a dirty trick in a method.
In this example, the location identifier of the word is its filename. The indexer used the combination of file update time and filename as the document ID. It can be fun to think about various key combinations such as the line number of the word in the document.
In addition to bound, there are lower_bound and upper_bound methods.
You can move the cursor to the upper or lower boundary of the key you are searching for using these methods. You can use these methods to do an “and” or “or” search as well. For example, you can combine two cursors. If both cursors point to the same point, then your “and” search is successful. If not, then move the slower cursor to the faster cursor to match using lower_bound. By repeating this process, you can do an “and” search without iterating through all lines. This might sound a bit complicated, so let’s try an example.
The following script is how you implement an “and” search using the lower_bound method. The script searches a line where both the words def and initialize appear. The filename and line number represent the location in this example.
| query2.rb | |
require 'rbtree' |
|
require 'nkf' |
|
|
|
class Query2 |
|
def initialize |
|
@tree = RBTree.new |
|
end |
|
|
|
def push(word, fname, lineno) |
|
@tree[[word, fname, lineno]] = true |
|
end |
|
|
|
def fwd(w1, fname, lineno) |
|
k, v = @tree.lower_bound([w1, fname, lineno]) |
|
return nil unless k |
|
return nil unless k[0] == w1 |
|
k[1..2] |
|
end |
|
|
|
def query2(w1, w2) |
|
f1 = fwd(w1, '', 0) |
|
f2 = fwd(w2, '', 0) |
|
while f1 && f2 |
|
cmp = f1 <=> f2 |
|
if cmp > 0 |
|
f2 = fwd(w2, *f1) |
|
elsif cmp < 0 |
|
f1 = fwd(w1, *f2) |
|
else |
|
yield(f1) |
|
f1 = fwd(w1, f1[0], f1[1] + 1) |
|
f2 = fwd(w2, f2[0], f2[1] + 1) |
|
end |
|
end |
|
end |
|
end |
|
|
|
if __FILE__ == $0 |
|
q2 = Query2.new |
|
while line = ARGF.gets |
|
NKF.nkf('-w', line).scan(/\w+/) do |word| |
|
q2.push(word, ARGF.filename, ARGF.lineno) |
|
end |
|
end |
|
q2.query2('def', 'initialize') {|x| p x} |
|
end |
|
Imagine you have Ruby code like this:
| query2_test.rb | |
class Foo |
|
# initialize foo |
|
def initialize(name) |
|
@foo = name |
|
end |
|
|
|
def foo; end |
|
def baz; end |
|
end |
|
|
|
class Bar < Foo |
|
# initialize bar and foo |
|
def initialize(name) |
|
super("bar #{name}") |
|
end |
|
def bar; end |
|
end |
|
This is the output when you run the script:
[demo4book (master)]$ ruby query2.rb query2_test.rb |
|
["query2_test.rb", 3] |
|
["query2_test.rb", 13] |
When two cursors do the initial key lookup, both of the cursors move to the first matching lines:
first cursor ["query2_test.rb", 3] second cursor ["query2_test.rb", 2] |
Then the cursor in the smaller number jumps to the same number.
# fwd(['initialize', fname, 3]) |
|
first cursor ["query2_test.rb", 3] second cursor ["query2_test.rb", 3] |
Once matched, move both cursors one forward.
first cursor ["query2_test.rb", 7] second cursor ["query2_test.rb", 12] |
Then move the smaller cursor. This time, it doesn’t have the same number, so it jumps to the next largest number.
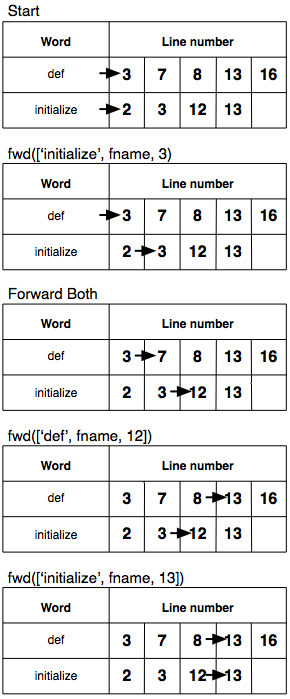
Figure 45. Skipping “and” search using rbtree
# fwd(['def', fname, 12]) |
|
first cursor ["query2_test.rb", 13] second cursor ["query2_test.rb", 12] |
By repeating this, you can do a skipping “and” search (see Figure 45, Skipping “and” search using rbtree for the detailed diagram).
There is another reason for using lower_bound and upper_bound methods instead of bound.
When you are dealing with a large number of elements, you need to put all of them into memory as an Array to use a bound method. If you move the scope of the range bit by bit using lower_bound, it will increase the frequency of method calls but can decrease the size of memory and the buffer of RMI for each method call.
RBTree is in fact used inside Drip as an ordered data structure. It is used as a union of the Drip key (integer key). It is also used as a union of tags. This union consists of an array of a [tag(String), key(Integer)] collection as keys.
['rbcrawl-begin', 100030] |
|
['rbcrawl-begin', 103030] |
|
['rbcrawl-fname=a.rb', 1000000] |
|
['rbcrawl-fname=a.rb', 1000020] |
|
['rbcrawl-fname=a.rb', 1000028] |
|
['rbcrawl-fname=a.rb', 1000100] |
|
['rbcrawl-fname=b.rb', 1000005] |
|
['rbcrawl-fname=b.rb', 1000019] |
|
['rbcrawl-fname=b.rb', 1000111] |
This will let you search the latest key with the rbcrawl-begin tag or the closest key to a cursor with rbcrawl-fname=a.rb with the cost of doing a binary search.
Rinda has strong pattern matching. However, its Array-based internal data structure had a scaling problem, because the search time increases linearly as data size grows (O(N)).[14] On the other hand, Drip uses RBTree internally so that you can access the starting point of the tag or key relatively quickly (O(log n)). Thanks to this data structure, you can program as if you don’t have to worry about the data growth. The nonconsumable queue and resetting the data with rbcrawl-begin are examples of such a programming attitude.