dRuby and Rinda: Implementation and application of distributed Ruby and its parallel coordination mechanism
($Revision: 1.44 $ / $Date: 2008/03/03 15:24:10 $)
_ Abstract
オブジェクト指向スクリプト言語Rubyは、記述のしやすさ、柔軟な動的性から、多くのプログラマに愛されている。昨今では、高い生産性を持つことで知られるWebアプリケーション開発フレームワークRuby on Rails(RoR)の流行とともに、ビジネスにおいても注目されつつある。
Rubyの活躍の場が、小さなツールから、大きなアプリケーションへと拡大して行くにつれて、Rubyの分散オブジェクト環境の必要性が増しており、その利用容易性、パフォーマンス、プラクティス例に関する情報が求められている。なお、Pragmatic Bookshelfは日本で出版されたdRubyの書籍を、英訳して出版することを計画している。
The object-oriented scripting language Ruby is loved by many programmers for being easy to write in, and for its flexible, dynamic nature. In the last few years, the Ruby on Rails web application framework, popular for its productivity benefits, has brought about a renewed attention to Ruby from the enterprise. As the focus of Ruby has broadened from small tools and scripts, to large applications, the demands on Ruby's distributed object environment have also increased, as has the need for information about its usage, performances and examples of common practices. An English translation of the author's Japanese dRuby book is currently being planned by the Pragmatic Bookshelf.
dRubyとRindaは、我々が開発したRubyの分散オブジェクト環境と共有タプルスペース実装であり、Rubyに標準添付されている。dRubyは、Rubyの特徴を維持しつつメソッドコールをネットワーク上に拡張するものであり、RindaはdRubyの仕組みを用いて分散協調システムの糊言語Lindaの機能をRuby上に提供する。この記事では、これらの設計ポリシーと実装についてポイントを解説し、そのシンプルさを実際のコード例と併せて示すとともに、実際に利用されているアプリケーションを紹介する。
このことにより、dRubyとRindaが分散システムのスケッチに適していることを示すと共に、実世界のアプリケーションを構築するインフラとしても実績を積みつつあることを示す。
dRuby and Rinda were developed by the author as the distributed object environment and shared tuplespace implementation for the Ruby language, and are included as part of Ruby's standard library. dRuby extends method calls across the network while retaining the benefits of Ruby. Rinda builds on dRuby to bring the functionality of Linda, the glue language for distributed co-ordination systems, to Ruby. This article discusses the design policy and implementation points of these two systems, and demonstrates their simplicity with sample code and examples of their usage in actual applications. In addition to dRuby and Rinda's appropriateness for sketching out distributed systems, this article will also demonstrate that dRuby and Rinda are building a reputation for being suitable as components of the infrastructure for real-world applications.
_ 1. Introduction
この記事はdRubyとRindaについて報告するものである。dRubyはRubyの分散オブジェクト環境であり、RindaはdRubyを用いた協調機構である。dRubyを紹介する前に、まずRubyについて述べる。
Rubyはまつもとゆきひろ氏によって開発されたオブジェクト指向スクリプト言語である。これまで先鋭的なプログラマから強く支持されていたが、昨今はその生産性の高さからビジネスとして利用する人々からも注目されるようになった。
This article aims at giving you details on dRuby and Rinda. dRuby provides distributed object environment for Ruby. Rinda is a coordination mechanism running on dRuby. First, I would like to introduce Ruby.
Ruby is an object-oriented scripting language created by Yukihiro Matsumoto.
Until recently, Ruby's popularity was limited to a small community of early-adopter programmers. Ruby is now rapidly gathering attention amongst business users for its potential productivity gains.
Rubyはには次のような特長がある。
- クラス、メソッドなど一般的なオブジェクト指向機能
- 全てがオブジェクト
- 変数に型がない
- 使い易いクラスライブラリ
- シンプルで馴染み易い文法
- ガベージコレクタ
- 豊富なリフレクション機能
- 言語レベルのマルチスレッド
Ruby has the following characteristics;
- Standard object-oriented features, such as classes and methods
- Everything is an object
- Untyped variables
- Easy-to-use libraries
- Simple, easy-to-learn syntax
- Garbage collector
- Rich reflection functionality
- User level thread
Rubyはいわゆる、動的なオブジェクト指向言語に分類される。全てがオブジェクトで、変数に型はなく、メソッドの結合は全て実行時に行なわれる。また、豊富なリフレクション機能を持ち、メタプログラミングも可能である。
Rubyは不思議な言語である。Rubyには作者の魔法がかかっているようだ。Rubyに誘導されるままにプログラミングすることでオブジェクト指向プログラミングの本質に近付いた気になれるのだ。
Ruby is so-called, categorized as a dynamic object-oriented language. Everything is composed of objects, and there is no type of variables. Unification of methods is all made at execution time. Furthermore, Ruby has rich reflection functionality and allows to use metaprogramming.
Ruby is a mysterious language, as if the creator made tricks on Ruby. We do programming as Ruby leads us, and without notice we feel like almost touching on the essence of object-oriented programming.
dRubyはこのRubyの分散オブジェクト環境である。dRubyはRubyのメソッド呼び出しをネットワーク上に拡張し、別のプロセス/マシンのオブジェクトのメソッドを呼び出せるようにする。そしてもう一つ、RindaはdRubyをベースにした分散協調システムの糊言語Lindaの実装で、共有タプルスペースを提供するものだ。
この記事は、dRubyの概念から設計ポリシー、実装と実世界の応用例まで紹介するものである。章の構成は次の通りである。
dRuby is a distributed object environment for making Ruby running on it. dRuby extends Ruby’s method calls across the network and enables to call object methods from other processes/machines. Another is that Rinda incorporates Linda’s implementations within itself; Linda is a glue language of a distributed coordination system based on dRuby, so it provides common tuple spaces. This article introduces not only dRuby’s concept and its design policy but also its implementations and practical usage. This article will be discussed as follows.
- the way of dRuby - dRubyの概要とその設計ポリシーについて
- Implementation - dRubyの実装の詳細について
- Performance - dRubyを使う場合のオーバーヘッドについて
- Application - dRubyを用いた実際のシステムと、Rindaの概要、Rindaを用いた実際のシステムについて
- the way of dRuby - dRuby's overview and its design policy
- Implementation – dRuby's implementations
- Performance - Overhead in using dRuby
- Application - A real system executing dRuby, Rinda's overview and a real system executing Rinda
_ 2. the way of dRuby
Twitterの開発者、Blaine Cookは彼のプレゼンテーション「Scaling Twitter」*1の中でdRubyについて次の様に述べた。
- Stupid Easy, Reasonably Fast
- Kinda Flaky, Zero Redundancy, Tightly Coupled.
彼の指摘は的確である。
この章ではdRubyの設計方針とdRubyの特徴について説明する。
Blaine Cook, lead developer of Twitter (a micro-blogging service), mentioned dRuby in his presentation, "Scaling Twitter". *2
- Stupid Easy, Reasonably Fast
- Kinda Flaky, Zero Redundancy, Tightly Coupled.
His points were an apt assessment.
In this chapter, I describe the design policy and characteristics of dRuby.
2.1. characteristics of dRuby.
dRubyはRubyのRMIを提供するライブラリの一つである。作者がdRubyの開発で目指したのは一般的な分散システムのRuby化ではない。Rubyのメソッド呼び出しを別のプロセスへ、別のマシンへ拡張することである。
結果として、できあがったdRubyはRubyインタプリタを他のプロセスへ、マシンへ、空間的に時間的に拡張するものとなった。
dRuby is one of several RMI libraries for Ruby. I did not aim for dRuby to be just another conventional distributed object system for Ruby. Rather, I intended to extend Ruby method calls to other processes and other machines.
As a result, dRuby extends the Ruby interpreter across other processes and other machines, both in a physical sense and a temporal sense.
dRubyには次のような特徴がある。
- Ruby限定
- pure Ruby
- IDLなどの定義が不要
さらに一般的な分散オブジェクトシステムの視点で言えば次の点も特徴となる。
- セットアップが簡単
- 習得が簡単
- 自動的なオブジェクト転送方式の選択 (値渡し or 参照渡し)
- Reasonably Fast
- サーバとクライアントの区別がない
dRuby has the following characteristics.
- exclusively for Ruby
- written purely in Ruby
- specifications, such as IDL, not required
From the perspective of a conventional distributed object system,
dRuby also has the following characteristics.
- Easy to set-up
- Easy to learn
- Automatic selection of object transmission strategy (pass by value or pass by reference)
- reasonably fast
- no distinction between server and client
dRubyはRuby専用の分散オブジェクトシステムである。Rubyで書かれたスクリプトしか扱えないが、Rubyが動作すればマシン、OSを問わず利用できる。利用できるとは、プラットフォームが異なっていたとしても、Rubyが動作すれば、お互いのオブジェクトのメソッドを利用し、オブジェクトを交換できるということである。
dRuby is a distributed object system exclusively for Ruby. The platforms which dRuby runs are able to exchange objects and also call methods on each other objects. dRuby can run on any machine that runs Ruby, irrespective of operating system.
Cなどで書かれた特別な拡張ライブラリではなく、全てRubyスクリプトで記述されている。Rubyには優れたスレッド、ソケット、マーシャリングのクラスライブラリが備わっているため、最初のバージョンのdRubyはわずか200行で実装されていた。この事実はRubyのクラスライブラリの強力さ、センスの良さを示すものである。現在のRubyの配布パッケージは、dRubyが標準で含まれており、RubyがインストールされているならすぐにdRubyを利用可能である。
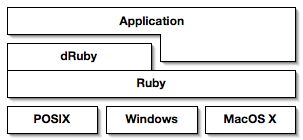
dRuby is written completely in Ruby, not a special extension written in C. Thanks to Ruby's excellent thread, socket and marshalling class libraries, the initial version of dRuby was implemented in just 200 lines of code. I believe that this demonstrates the power and elegance of Ruby's class libraries. dRuby is currently included as part of the standard distribution of Ruby as one of its standard libraries, so it dRuby is available wherever Ruby is installed.
2.2. Compatibility with Ruby
dRubyはRubyスクリプトとの互換性にとくに注意を払っている。多くのRubyの特徴を変えることなく、そのまま残している。dRubyはRubyプログラマにとって、親しみやすく、シームレスな存在であるが、一般的な分散オブジェクトシステムのプログラマからは奇妙に感じられるかもしれない。
dRuby pays special attention to maintaining compatibility with Ruby scripts. dRuby adds a distributed object system to Ruby while preserving as much of the "feel" of Ruby as possible. Ruby programmers should find dRuby to be a comfortable, seamless extension of Ruby. Programmers accustomed to other conventional distributed object systems, however, may find dRuby to be a little strange.
Rubyの変数には型がなく、継承関係による代入の規則がない。静的な型を持つJavaなどのように実行前にオブジェクトの正当性を検証せず、メソッドの検索はすべて実行時(メソッド呼び出し時)に行われる。この性質はRubyの大きな特徴の一つである。
dRubyにおいても同様である。dRubyのクライアントスタブ(dRubyでは参照、DRbObjectと呼ぶ)にも型はなく、メソッドの検索はすべて実行時に行われる。公開されたメソッドの一覧や、継承情報などを事前に互いに知っておく必要がないのである。このため、IDLなどによるインターフェイス定義を必要としない。
Variables in Ruby are not typed, and assignment is not restricted by inheritance hierarchies. Unlike languages with statically checked variables, such as Java, objects are not checked for correctness before execution, and method look-up is only conducted at execution time (when methods are called). This is an important characteristic of the Ruby language.
dRuby operates in the same fashion. In dRuby, client stubs (the DRbObject, also called the "reference" in dRuby) are similarly not typed, and method look-up is only conducted at execution time. There is no need for a listing of exposed methods or inheritance information to be known in advance. Thus, there is no need to define an interface (e.g. by IDL).
dRubyはRubyのメソッド呼び出しをネットワーク上に拡張する以外には、できるだけRubyの仕様を変更しないように、汚染しないように注意されている。この指針によって、Rubyの特徴を存分に享受できるのである。
たとえば、イテレータと呼ばれるブロック付きメソッドも利用できるし、例外もそのまま使用できる。mutexやqueueなどのスレッド間同期メカニズムも、そのままプロセス間の同期に使うことができる。
Aside from allowing method calls across a network, dRuby has been carefully developed to adhere as closely to regular Ruby behaviour as possible. Consequently, much of unique benefits of Ruby are available for the programmer to enjoy.
For example, methods called with blocks (originally called iterators) and exceptions can be handled as if they were local. Mutex, queues and other thread synchronization mechanisms can also be used for inter-process synchronization without any special consideration.
2.3. Passing Objects
Rubyに存在しない概念は、できるだけ自然に感じられるように導入された。
例えば、オブジェクトの転送方式である。メソッド呼び出しの際に引数や、戻り値、例外などオブジェクトが転送される。引数はクライアントからサーバへ、戻り値や例外はサーバからクライアントへのオブジェクトの転送である。この記事ではこれらの転送をまとめてオブジェクトの交換と呼ぶことにする。
Concepts that didn't originally exist in Ruby were introduced in dRuby as naturally as possible.
Object transmission is a good example. When methods are called, objects such as the method arguments, return values and exceptions are transmitted. Method arguments are transmitted from client to server, while exceptions and return values are transmitted from server to client. In this article, I will refer to both of these types of object transmission as object exchange.
Rubyの変数の仲間に代入(あるいは束縛)できるのは、参照だけである。オブジェクトのクローンが代入されることはない。しかし、dRubyにおいては違う。おそらく、分散オブジェクトの世界では「値を渡す」「参照を渡す」といった違いが存在してしまうことは避けられないだろう。この違いはdRubyも同様に避けられない。
Assignment (or binding) to variables in Ruby is always by reference. Clones of objects are never assigned. It is, however, different in dRuby. In the world of distributed objects, distinguishing between "pass by value" and "pass by reference" is an unavoidable fact of life. This is true also of dRuby.
永遠に(あるいはnilになるまで)参照を交換し合う計算モデルも考えられるが、現実的なアプリケーションではいつか「値」が必要になる。
dRubyではできるだけプログラマに転送方式の違いを意識させず、かつ現実的な効率のよさを考慮した仕組みを用意した。dRubyではプログラマが明示的に参照渡し、値渡しを指示するのではなく、システムが自動的に判断して参照渡し、値渡しを選択するのである。オブジェクトがシリアライズ可能かどうかをその判断の基準とした。
While a computing model where references are continually exchanged forever (or until they become nil) is conceivable, in reality applications will, at some point, need "values".
The mechanism provided by dRuby minimizes the need for programmers to care about the difference between types of object exchange, while also striving to be reasonably efficient. In dRuby, programmers do not need to explicitly specify whether to use pass-by-value or pass-by-reference. Instead, the system automatically decides which to use. This decision is made using a simple rule -- serializable objects are passed by value, while unserializable objects are passed by reference.
常にこの判断が正しいとは言えないが、多くの場合にうまく動作する。この規則について少し述べたい。まず、シリアライズ不能なオブジェクトは値渡し不能であるので考えない。問題となるのは、参照渡しにしたほうが都合がよいものが、値渡しとなるケースである。このために、dRubyはシリアライズ可能なオブジェクトを参照渡しであると表明する機能を用意した。実際の利用例は後で述べる。
Although this rule may not always be correct, in most situations it will work. Here, I would like to briefly discuss this rule. Firstly, note that it is impossible for objects that cannot be serialized to be passed by value. The problematic case is where a serializable object that is more appropriately passed by reference is instead passed by value. To handle this case, dRuby provides a mechanism whereby serializable objects can be explicitly marked to be passed by reference. An example will be discussed later in this article.
この自動的なオブジェクトの転送方式の選択機能によって、dRubyではオブジェクトの転送方式に関してプログラマが書かなくてはならないスクリプトをきわめて少ないものとしている。
By automatically choosing the means of object transmission, dRuby minimizes the amount of code that needs to be written to handle object transmission.
IDLなどのインターフェイス定義やオブジェクトの転送方法の宣言などの他にも、他の分散オブジェクトシステムと異なっている点は少なくない。dRubyは「Rubyのような分散オブジェクトシステム」となることを目指しているからである。まさに「Kinda Flaky」である。
dRuby's lack of a need for interface definition (e.g. IDL) and declaration of object transmission style, are not the only ways that dRuby differs from other distributed object systems. This is because dRuby aims to be a "Ruby-like distributed object system", and perhaps also why dRuby may be perceived as being "kinda flaky".
2.4. Unsupported things
最後にdRubyがサポートしていない事柄も紹介しなくてはならないだろう。GCとセキュリティだ。
dRubyでは分散GCを実装していない。安価で現実的な解決案がまだ見つからないためだ。
現在のところ、GCされないように気をつけるのはアプリケーションの責任である。ping方式によってGCから保護する方法はオプションとして用意されるが、循環参照によって消えないオブジェクトが生まれる可能性がある。Rubyインタプリタに手を加えて、この問題を解決する研究も行われている。
dRubyはセキュリティに関してもなにもしない。Rubyにならい、Rubyと同様なメソッドの可視性の制御は行われる程度であり、悪意のある攻撃に対して無力である。なお、通信経路としてSSLを選ぶことは可能である。
Finally, I shall introduce some of the features that dRuby does not support, namely garbage collection and security.
dRuby does not implement distributed garbage collection because I have not found a solution that is both cheap and realistic.
Currently, it is the responsibility of the application to prevent exported objects from being garbage collected. The option to protect objects from garbage collection using a ping mechanism has been provided, however, there is a risk that circular references will give rise to objects that never get garbage collected. Possible solutions to this problem, including the modification of the Ruby interpreter, are currently being explored.
dRuby currently does not provide any mechanisms for security. At most, dRuby imposes the same restrictions on method visibility as Ruby does, but is helpless against malicious attacks. It is, however, possible to use SSL to secure network communications.
本章ではdRubyの設計指針について説明した。
dRubyはRubyのメソッド呼び出しをそのまま拡張するものであり、一般的なRMIのRuby風インターフェイスではない。だからこそdRubyとXML-RPC、SOAP、CORBAなどと競合するものではなく、むしろ共存するものであると考える。実際、外部のネットワークとのインターフェイスとしてhttpを使い、そのバックエンドにdRubyで構成された内部システムを持つものも多い。
In this chapter, I described dRuby design policy.
To summarize, dRuby does extend Ruby's method calls as it is, so dRuby is not just a standard Ruby-like interface of RMI. dRuby would rather co-exist with XML-RPC、SOAP、CORBA e.g. In fact, some use http as interface for external network and where dRuby is incorporated in their internal systems at the backend.
_ 3. Implementation
本章ではdRubyの特徴的な機能と実装について述べる。
基本的なRMIの実現方法、オブジェクト転送の機構について、dRubyの最初のバージョンのコードと、サンプルコード使って詳細に説明する。
In this chapter, I discuss some interesting features of dRuby and its implementation.
Using code from the initial version of dRuby and other sample code, I will describe in detail how basic RMI is and the mechanism of object transmission.
3.1. Basic RMI
まず、メソッド呼び出しの基本的な事項について、実際のコードで紹介し、その実装を説明する。
First, I shall explain the implementation of basic method calling using the actual code.
3.1.1. An Example: The producer-consumer problem
以下のコードは典型的な生産者消費者問題を示す共有Queueの実装例である。
The following code is a typical implementation the producer-consumer problem using a shared queue.
# shared queue server
require 'thread'
require 'drb/drb' # (1)
queue = SizedQueue.new(10) # (2)
DRb.start_service('druby://localhost:9999', queue) # (3)
sleep # (4)
はじめに共有queueサーバを説明する。
dRubyを利用するアプリケーションははじめに'drb/drb'をロードする(1)。
次にバッファの要素数に制限を付けられる、SizedQueueオブジェクトを生成する(2)。
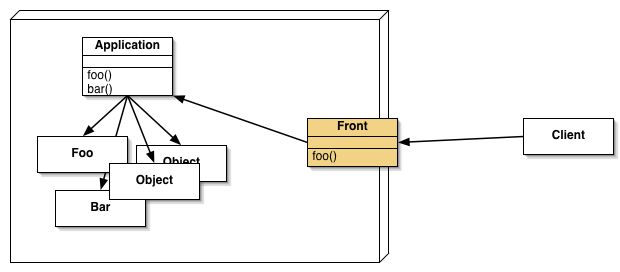
そして、DRbのサービスを開始する(3)。DRb.start_serviceは、他のプロセスに公開したいオブジェクトと、そのURIを与えることができる。この呼び出しは、'druby://localhost:9999'というURIで、SizedQueueオブジェクトを公開することを示している。
dRubyによって作られるシステムでは、どこかに必ず、システムの入り口を示すオブジェクトが存在する。そのオブジェクトをfrontオブジェクトと呼ぶ。
First, I shall explain the shared queue server.
Applications using dRuby must start by loading 'drb/drb' (1). Next, a SizedQueue object (2) with a limited number of buffer elements is instantiated. Then the DRb services is started (3). DRb.start_service is given the objects to be made public by dRuby, as well as the URI for the service. In this case, the SizedQueue object is made public at the URI "druby://localhost:9999".
Any systems created by dRuby always have an object that indicates the system entrance. The object is called as a front object.
最後に、サービスが終了してしまわないようにsleepで停止する(4)。メインスレッドが停止していても、バックグラウンドのスレッドがサービスを提供し続けるので問題ない。
Finally, the service is stopped, without exiting, by calling sleep(4). Even though the main thread is stopped, the service continues to be available as it continues to run on threads in the background.
# producer
require 'drb/drb'
DRb.start_service #(1)
queue = DRbObject.new_with_uri('druby://localhost:9999') #(2)
100.times do |n|
sleep(rand)
queue.push(n) #(3)
end
# consumer
require 'drb/drb'
DRb.start_service
queue = DRbObject.new_with_uri('druby://localhost:9999')
100.times do |n|
sleep(rand)
puts queue.pop #(4)
end
クライアント的なアプリケーションもDRb.start_serviceを行う(1)。引数のないDRb.start_serviceは、frontを持たないアプリケーションであることを表す。なお、アプリケーションが参照オブジェクトを絶対に送り出さない場合にはDRb.start_serviceは不要となる。
分散queueの参照オブジェクトを生成する(2)。DRbObjectはリモートのオブジェクトを参照するproxyで、URIを伴って生成すると、そのURIに関連づけられたオブジェクトへの参照となる。
そしてリモートのオブジェクトにメッセージを送信する(3)。
The client-like producer and consumer applications also call DRb.start_service (1). A call to DRb.start_service without any arguments indicates that the application has no front object. Note that applications that never export an object do not need to call DRb.start_service.
Next, the reference object for the distributed queue is instantiated (2). DRbObjects are proxies referencing remote objects. A DRbObject instantiated with a URI references the object associated with that URI.
Messages are then sent to the remote object (3).
実行するには三つのターミナルを用意して順に起動するだけである。特別なセットアップはなにもない。
This example can be executed by preparing three terminals, and executing the scripts in order in separate terminals. No other special set-up is required.
% ruby queue.rb
% ruby consumer.rb
% ruby producer.rb
この小さなサンプルコードから、わずか数行で普通のRubyオブジェクトを共有することができるのがわかるだろうか。
dRubyはRubyでアプリケーションを書くように、簡単に分散システムを記述することができ、分散システムのアーキテクチャのスケッチや学習に最適である。さらにそのまま実運用可能なシステムとすることもできる。
This simple example demonstrates how Ruby objects can be shared between processes in just a few lines of code.
It is easy to write a distributed system in dRuby, just as it is easy to write applications in Ruby. Not only is dRuby suitable for writing distributed systems for prototyping or learning architectures, but such systems can also be implemented for use in production.
3.1.2. Implementation of RMI
以下、初版のdRubyのコード*3を引用しながら、dRubyのRMIの実装について説明する。初版のコードは細かい部分が記述されていないので、本質となる部分を見つけやすい。
リモートオブジェクトの参照オブジェクト - DRbObject - にメッセージを送信すると、そのメッセージはレシーバの識別子とともにリモートのdRubyサーバへ転送される。dRubyサーバはレシーバ識別子からオブジェクトを検索し、メソッドを起動する。初版のdRubyのDRbObjectを見てみよう。
This section explains dRuby's implementation of RMI using code from the first version of dRuby*4.
The first version of dRuby is easy to understand, as it does not cover as much of the complexity as later versions.
When messages are sent to the DRbObject (the object referencing remote objects), the message is forwarded to the dRuby server along with the receiver's identifer. The dRuby server looks up the object using the receiver's identifier and invokes the method. Let's have a look at the implementation of DRbObject in the first version of dRuby.
class DRbObject
def initialize(obj, uri=nil)
@uri = uri || DRb.uri
@ref = obj.id if obj
end
def method_missing(msg_id, *a)
succ, result = DRbConn.new(@uri).send_message(self, msg_id, *a)
raise result if ! succ
result
end
attr :ref
end
DRbObjectにはmethod_missingメソッドだけが定義されている。method_missingは、レシーバが処理できないメッセージを受け取った時に起動されるメソッドである。DRbObjectのmethod_missingは、オブジェクトの存在するdRubyサーバと接続し、レシーバのIDとメソッド名、引数を送信したのち、結果を返す。
つまり、DRbObjectに定義されていないメソッドは、全てリモートに転送されるのである。
先ほどのスクリプトの「push」「pop」がその例である。これらはDRbObjectに定義されていないので、method_missingが呼び出される。そして、URIで指定されたdRubyサーバに対してメッセージを転送する。
The only method defined in DRbObject is method_missing. In Ruby, method_missing is the method called when the receiver object receives an unknown method -- i.e. a "missing method" is invoked. The method_missing in DRbObject connects to the dRuby server, sends the ID of the corresponding receiver object and the name of the invoked method, and then returns the result.
In other words, any method that isn't defined in DRbObject is forwarded to the remote object.
The methods "push" and "pop" in the earlier script are examples of this. These methods are not defined in DRbObject, so method_missing is invoked, and the message is forwarded to the dRuby server specified by the URI given on initialization.
class DRbServer
...
def proc
ns = @soc.accept
Thread.start(ns) do |s|
begin
begin
ro, msg, argv = recv_request(s)
if ro and ro.ref
obj = ObjectSpace._id2ref(ro.ref)
else
obj = DRb.front
end
result = obj.__send__(msg.intern, *argv)
succ = true
rescue
result = $!
succ = false
end
send_reply(s, succ, result)
ensure
s.close if s
end
end
end
...
end
上の疑似コードはdRubyサーバの主処理である。
ソケットをacceptした後、スレッドを生成、オブジェクトの識別子、メッセージ、引数を受信する。そして、識別子に対応するオブジェクトを検索して、受信したメッセージを送信する。
多くの分散オブジェクトシステムでは、レシーバのクラスごとに、転送可能なメッセージの一覧を定義したproxyを用意することが多い。
しかしdRubyではmethdo_missingの仕組みと、実行時にメソッド検索をする機構によって一種類のproxyが全てのクラスのクライアントスタブとして機能する。
リモートのレシーバ(つまり本来のオブジェクト)が処理できないメッセージを受信した場合には、通常のRubyオブジェクトに対する操作と同様にNameError例外がraiseされる。
The pseudocode above describes the main behavior of the dRuby server.
After ''accept''ing a socket, a new thread is created and the object's identifier, message and arguments are received. After finding the object corresponding to the identifier, the received message is sent to it.
In most distributed object systems, it is common for a proxy defining the forwardable methods to be prepared for the class of each receiver. In dRuby, however, the usage of Ruby's method_missing method and runtime method lookup mechanism allows a single kind of proxy to act as the client stub for all classes.
When the remote receiver (i.e. the original object) receives a message it cannot handle, it raises a NameError exception -- the same behavior as a regular Ruby object.
メッセージごとにスレッドを生成する点にも注目して欲しい。スレッドを生成する利点は、独立した実行コンテキストを用意することで例外に強くなる、ネットワークIOのブロックを避ける、などいくつかある。その中でもっともユーザに恩恵があるのは、多重のRMIを許す点である。
先ほどの生産者消費者問題のプログラムがデッドロックしないのは、ここに秘密がある。消費者によるpopでDRbServerの処理がブロックしている最中にも、生産者によるpushを実行できるからである。dRubyはRMI中であっても、RMIを許すように作られている。これによってコールバック風の処理もイテレータも再帰呼び出しも動作し、スレッド同期メカニズムもプロセス間で利用できる。
Notice that a new thread is created for each individual message. Creating threads has a number of advantages, such as reducing the likelihood of exceptions by providing an independent execution context and avoiding network IO blocking. The greatest advantage for users, however, is that multiple RMI is permitted.
This is the reason why the earlier producer-consumer problem program does not deadlock. When the pop invoked by the consumer causes the DRbServer to block, the producer is still able to push. Even when dRuby is in the middle of an RMI, it is still possible to RMI. As a result, callback style execution, iterators and recursive calls will work in dRuby, as well as the usage of thread synchronization mechanisms across processes.
3.2. Message format
この節では、メッセージの書式とオブジェクトの交換方法について説明する。
This section describes the message format and the mechanism for object exchange.
dRubyはネットワークとしてTCP/IPを、メッセージのエンコード方法としてMarshalクラスライブラリを用いる。*5
dRuby uses TCP/IP for networking and the Marshal class library as its encoding mechanism. *6
MarshalはRubyに組み込まれたユニークなオブジェクトのシリアライズライブラリである。与えたオブジェクトを起点に参照を順にたどり、関係する全てのオブジェクトをシリアライズする。dRubyでは積極的にMarshalを利用する。
「Serializable」特性を持っているものだけをシリアライズ可能と考えるシステムが多いが、Rubyでは逆に基本的にどのオブジェクトもシリアライズ可能なものと考える。そして、シリアライズして意味がないもの、シリアライズできないもの、例えばFileやThread、Procなどに出会うと例外が発生する。
Marshal is a unique object serialization library, included as part of Ruby's core libraries. Starting from the supplied object, Marshal traces references one-by-one to serialize the entire graph of related objects.
dRuby makes heavy usage of the Marshal library. In some systems, only objects with the "Serializable" property are considered to be serializable. In Ruby, however, all objects are initially considered to be serializable. When Ruby encounters an object whose serialization is meaningless, or when serialization proves to be impossible (such as File, Thread, Proc, etc.), an exception will be raised.
リモートに転送されるリクエストは次の情報の組であり、それぞれのパートはMarshalでシリアライズしたオブジェクトである。
The request forwarded to remote object is composed of the following set of information. Each component is an object serialized by Marshal.
- receiver identifier
- message string
- arguments
初版の実装を見てみよう。現在のバージョンでは長さ情報も送信しているが本質的な違いではない。
Let's have a look at the implementations of the first version The latest version also sends length, but it does not have any difference in essence.
def dump(obj, soc)
begin
str = Marshal::dump(obj) # (1)
rescue
ro = DRbObject.new(obj) # (2)
str = Marshal::dump(ro) # (3)
end
soc.write(str) if soc
return str
end
この短いコードがdRubyの実装のもう一つのミソ(英語だとなに??)である。
まず、引数のオブジェクトをMarshalを使ってdump()する(1)。もし例外が発生した場合には、そのオブジェクトへの参照オブジェクト、つまりDRbObjectを生成して(2)それをMarshal.dumpする(3)。
Marshal.dumpが失敗するということは、シリアライズできないオブジェクト、あるいは、シリアライズできないオブジェクトを参照しているオブジェクトであることを示す。
dRubyではこの場合、RMIを失敗させない。シリアライズできないオブジェクト、つまり値として渡せないオブジェクトは、そのオブジェクトの参照を代わりに渡すのである。
この振舞いがdRubyとRubyのギャップを減らすための魔法の一つとなっている。
This short snippet of code is one of the distinguishing parts of dRuby's implementation.
First, the object passed as an argument is serialized using Marshal.dump(1). In the case that an exception is raised, the reference to the object (i.e. the DRbObject created (2) with the object) is serialized using Marshal.dump. (3)
When Marshal.dump fails, this means that the target object was unserializable, or an unserializable object was referenced by the target object.
In this case, dRuby does not allow the RMI to fail. Unserializable objects, or objects that cannot be passed as values, are instead passed as references to the object.
This behavior is one of the tricks that dRuby uses to minimize the gap between dRuby and vanilla Ruby.
少し実験してみよう。
共有の辞書を用意し、一方がサービスを辞書へ登録し、もう一方がサービスを利用する例を示す。
Let's see it in action.
In this example, we will prepare a shared dictionary. One service registers services in the dictionary, while another service uses the services in the dictionary.
まず辞書サービスである。分散システム風に言うと、name serverかもしれない、。
単にHashを公開するだけなので大変短い。
We'll deal with the dictionary service first. In distributed systems parlance, we might refer to it as the name server.
Since we're just making a Hash public, it's very short.
# dict.rb
require 'drb/drb'
DRb.start_service('druby://localhost:23456', Hash.new)
sleep
次にログサービスを示す。時刻と文字列を記録する簡単なサービスである。
主処理はSimpleLoggerクラスに定義される。
起動すると辞書サービスにサービスの説明とSimpleLoggerオブジェクトを登録してsleepする。
SimpleLoggerクラスはFileオブジェクト(このスクリプトでは標準エラー出力)を参照しているため、Marshal.dumpできない。このため、値渡しはできず、参照渡しとなるはずである。
Next is a log service. This is a simple service that records a time and a string.
The SimpleLogger class defines the main logic.
Running logger.rb will register a SimpleLogger object and a description to the dictionary service, and then sleep.
Since the SimpleLogger references a File object (in this script, standard error output), it cannot be serialized with Marshal.dump. Consequently, it cannot be passed by value, and is passed by reference instead.
# logger.rb
require 'drb/drb'
require 'monitor'
DRb.start_service
dict = DRbObject.new_with_uri('druby://localhost:23456')
class SimpleLogger
include MonitorMixin
def initialize(stream=$stderr)
super()
@stream = stream
end
def log(str)
s = "#{Time.now}: #{str}"
synchronize do
@stream.puts(s)
end
end
end
logger = SimpleLogger.new
dict['logger'] = logger
dict['logger info'] = "SimpleLogger is here."
sleep
利用者側を説明する。
辞書サービスへの参照を生成し、loggerの説明とloggerを取得する。それぞれのオブジェクトをinspectすると、infoは"SimpleLogger is here."という文字列オブジェクトであるが、loggerはDRbObjectであることがわかる。
Finally, I will explain the service user.
The script app.rb creates a reference to the dictionary service and retrieves the logger service using the logger's description string. After inspecting each object with the p method, the info object is simple the string object "SimpleLogger is here.", while the logger object is revealed to be a DRbObject.
# app.rb
require 'drb/drb'
DRb.start_service
dict = DRbObject.new_with_uri('druby://localhost:23456')
info = dict['logger info']
logger = dict['logger']
p info #=> "SimpleLogger is here."
p logger #=> #<DRb::DRbObject:0x....>
logger.log("Hello, World.")
logger.log("Hello, Again.")
logger.log()はログを出力するRMIである。logger.rbを起動した端末の標準出力にログが出力されたのが観察できるであろう。
logger.log() is an RMI that generates log output. We should be able to check the output in the terminal running logger.rb.
この章ではdRubyの実装の特徴的な点から、メソッド呼び出しの実装方法と、メッセージの形式とオブジェクトの転送方式の選択機構の実装方法の二点を、動作するスクリプトを交えて説明した。
実装についてdRubyの初版のスクリプトから抜粋したが、現バージョンもエッセンスは変わっていない。dRubyの実装を観察するには初版のスクリプトが適している。
In this chapter, I described two distinguishing features of dRuby's implementation with usable examples: the method call implementation, and the implementation of the mechanism for selecting the method of object transmission and message format.
Extracts from the first version of dRuby were used in the explanations, but the reader should be aware that the essence of the implementation remains unchanged in the current version. The first version of dRuby is the most suitable for reviewing the implementation.
_ 4. Performance
この章ではdRubyのRMIの性能についての実験結果を報告する。
In this chapter, I discuss results from testing dRuby's RMI performance.
同一マシン上のプロセス間でRMIが最大どのくらい可能であるかのデータを示す。この実験はよくあるケースでの使用例というよりも、ベストなケースでの値と考える。dRubyによってどの程度のオーバヘッドが発生するかの参考になるだろう。
The data produced by the following experiment indicates the maximum possible number of RMI between processes on the same machine. The results from this experiment should be considered to be for a best-case scenario, and not results for typical usage. The results should give a good reference for the degree of overhead in dRuby.
require 'drb/drb'
class Test
def count(n)
n.times do |x|
yield(x)
end
end
end
DRb.start_service('druby://yourhost:32100', Test.new)
sleep
require 'drb/drb'
DRb.start_service(nil, nil)
ro = DRbObject.new_with_uri('druby://yourhost:32100')
ro.count(10000) {|x| x}
10000回のRMIにかかった時間を二つの環境で測定した。
まず、同一マシンのホストOSと仮想マシンのゲストOSによる通信について報告する(Pentium4 3.0GHz)。Windows XPのRubyと、そのWidnowsの中でゲストOSとして動作するcoLinuxで動くRubyの組み合わせである。
I measured the time taken for 10,000 remote method invocations in two different environments.
The first case measures transmission between guest OS running on a virtual machine on a host OS, and the host OS on the same machine (Pentium4 3.0GHz). This combination is Ruby on Windows XP, and Ruby on a coLinux instance running as a guest OS within the Windows XP host OS.
% time ruby count.rb real 0m11.250s user 0m0.810s sys 0m0.260s
なお、これをRMIを使わず、同じプロセスないの通常のメソッド呼び出しとして実験すると次のようになる。
For the following set of results, RMI is not used. Instead, regular method calls within the same process were tested.
% time ruby count.rb real 0m0.044s user 0m0.040s sys 0m0.010s
同様のテストをiMac G5で実行した結果を載せる。前者は同じOS上の別のプロセスでの結果、後者は通常のメソッド呼び出しの結果である。
The next two sets of results are from executing the tests on an iMac G5. The first set of results are with separate processes on the same OS, while the second set of results used regular method calls within a single process.
real 0m13.858s user 0m6.517s sys 0m1.032s
real 0m0.079s user 0m0.031s sys 0m0.012s
一秒間に700-900回のRMIが可能であった。この速度があなたのアプリケーションで十分な速度かどうか、検討してみてほしい。なお、RMIを使わず同一プロセス内でのメソッド呼び出しは200倍前後高速である。RMIの回数はアプリケーションの性能に大きく影響することと予想できる。実際のアプリケーションを作成する場合には、このことを考慮しなくてはならない。
Between 700 - 900 remote method invocations per second were achieved. Whether this is sufficient for your application is for you to decide. Note that regular method calls within the same process (without RMI) were approximately 200 times faster. The frequency of RMI is likely to have a significant impact on application performance, and is an important point to consider when building real applications.
_ 5. Applications
dRubyを用いて実装されたアプリケーションはいくつかある。
Ruby on Railsではデバッガの実装、Webアプリケーションの非同期処理などで数多く利用されていることはよく知られている。
この章ではdRubyを用いたアプリケーションの例をいくつか紹介する。また、dRubyをベースとした分散協調システム、Rindaとその応用例についても言及する。
There are a few applications that made implementations by using dRuby.
As is well known, in the Ruby on Rails debugger is implemented and in asynchronous process of Web applications where dRuby are often implemented.
In this chapter, I introduce a few applications which made implementations by using dRuby. On top of that, I also discuss a distributed coordination system based on dRuby, Rinda and a practical example.
5.1. Backend service of large scale Web application
大規模Webアプリケーションのバックエンドの例として、RubyKaigi 2006において、舘野氏によって報告されたはてなスクリーンショットサービスを紹介する。スクリーンショットサービスは登録されたURLのスクリーンショットを、blogなど他のはてなのサービスにサムネイルなどを表示するものである。
WebフロントエンドはLinux上に構築されるが、スクリーンショットの撮影はWindowsのIEコンポーネントを用いて実現する。Windowsで撮影するのは、Windows環境の方が高速にスクリーンショットを撮影できるためである。
スクリーンショットはフロントエンドとは非同期にバッチ処理として実行される。
Windows上で動作するプロセスは、Linux上のプロセスからdRubyを介してURLと返却方法をオブジェクトとして受け取り、スクリーンショットを撮影する。
Windowsマシンは2台用意され、並列に処理が行なわれる。スピードが必要になったらWindowsマシンを追加すればよく、ある程度スケーラビリティが確保されている。
Here, I introduce Hatena screenshot service as an example of a backend use in large scale Web applications. Hatena screenshot service is a service reported by Tateno in Ruby Kaigi 2006. The screenshot service is to display thumbnails e.g. of registered URL screenshots to other Hatena service like blogs.
Web front end is configured on Linux, but screenshot is implemented based on Windows IE components, because taking the screenshot under Window's environment achieves better performance at high speed.
The screenshot is executed as asynchronous batch process from a front-end.
Processes running on Windows receive objects of both a URL from processes on Linux via dRuby and a return method, and execute the screenshot.
2006年のRubyKaigiの発表当時のデータによると、このシステムの扱う問題の規模は、2台の並行処理により120screenshot(ss)/min、170,000ss/dayとのことである。
According to data as of 2006 that RubyKaigi present, the handling scale in this system was likely 120SS/min, 170,000SS/day by parallelism with 2 machines.
5.2. On-Memory Database, or Persistent Process
次に、永続化されたメモリ、あるいは永続的なプロセスとしての使い方を紹介しよう。Webアプリケーションの問題の多くは短命なリクエスト−レスポンスを扱うプロセスと、意味的なプロセスの両方がある、という点にある。
具体的な例としてCGIをあげる。CGIは一つのリクエストとともに起動され、レスポンスを返して終了する小さなプロセスである。しかし、ユーザがウェブブラウザを通じて感じているアプリケーションはもっと長いライフサイクルを持っている。たくさんの小さなリクエストとレスポンスを通じて、一つのアプリケーションをずっと使っているかのように見せかけるために、CGIは次の世代のCGIのための遺言を残しながら死んでいく。
遺言の管理はWebアプリケーション・プログラミングにおいてもっとも苦労する部分の一つである。状態のシリアライズ、ファイルやRDBの排他制御、複数の相続者による競合など、考慮しなくてはならない事柄が多いのである。
短い寿命のフロントエンドと、長い寿命のアプリケーションを組み合わせることで、この遺言そのものを必要としない、あるいは遺言を極小にする作戦がある。
Next, I shall introduce the usage of dRuby as persistent memory, or as a persistent process. Many problems in web applications relate to the need for both processes that deal with short-lived request-response cycles, and semantic processes.
One concrete example is CGI. CGI programs are invoked upon receiving a single request, and finish after returning a response. From the point of view of the user on their web browser, however, the application appears to have a much longer life-cycle. In order to make a series of small request-response cycles feel like a single long-lived application, each CGI instance must leave a "will" to the next generation before it dies.
The management of these "wills" (session management) is one of the major pain points in web application programming. Many factors need to be taken into account -- the serialization of state, handling mutual exclusion in files or relational databases, and dealing with conflicts arising from multiple, simultaneous requests.
One approach is to minimize, or even eliminate, the "will" left for the next process by combining the short-lived front-end with a long-lived, persistent application.
RWikiはちょっと奇妙なWikiWikiWebサーバで、そのようなアーキテクチャを採る。
Wikiページのソース、それをHTML化したキャッシュ、リンクや更新時刻などのメタ情報を全て長生きするサーバのメモリに持ち続ける。そして短命なCGIはこのサーバとdRubyを介して問い合わせユーザにWikiページを提供する。ある非公開のRWikiでは約20000ページをオンメモリでホストする。(RWikiサーバの再起動に備え、サイトを再構築するのに十分な情報をログしつづける。ただし、実行中はそのログを参照することはない)
RWiki is an interesting WikiWikiWeb implementation that applies such an architecture.
Meta-data such as the source of the Wiki page, the cache of the HTML output, links and update time stamps, are all maintained in memory on a long-lived server process. The short-lived CGI processes access this server via dRuby to retrieve Wiki pages requested by the user. One private RWiki server hosts approximately 20,000 pages in memory. In order to be able to rebuild the site after a reboot, the server constantly logs sufficient data on disk. These logs, however, are never referenced during normal execution.
極小のCGIスクリプト(4steps)と簡単なカウンターサーバの例を示す。CGIの仕組みを思い出して欲しい。CGIはWebサーバなどCGIの環境から、標準入力(stdin)、環境変数(environment variable)を通じてHTTPのリクエストを取得し、標準出力(stdout)を通じてレスポンスを返却するものだ。
このCGIスクリプトは相対的に長生きなカウンターサーバに、環境変数、標準入出力の参照を与えて処理を依頼する。永続化するカウンターの代わりに、あなたのアプリケーションを起動すれば、遺言モデルではないCGIアプリケーションが簡単に記述できるだろう。
The following example is an extremely small CGI script (4 steps), along with a simple "counter" server. Let's quickly review the mechanism of CGI. CGI process retrieves a HTTP request from a CGI environment (typically a web server) via standard input (stdin) and environment variables, and then returns a response through standard output (stdout).
This CGI script invokes the comparatively long-lived counter server and passes it the environment variables and references to the standard output and input. By replacing the counter example with another example, a CGI application that doesn't use the "will" model can easily be written.
#!/usr/local/bin/ruby
require 'drb/'drb'
DRb.start_service('druby://localhost:0')
ro = DRbObject.new_with_uri('druby://localhost:12321')
ro.start(ENV.to_hash, $stdin, $stdout)
require 'webrick/cgi'
require 'drb/drb'
require 'thread'
class SimpleCountCGI < WEBrick::CGI
def initialize
super
@count = Queue.new
@count.push(1)
end
def count
value = @count.pop
ensure
@count.push(value + 1)
end
def do_GET(req, res)
res['content-type'] = 'text/plain'
res.body = count.to_s
end
end
DRb.start_service('druby://localhost:12321', SimpleCountCGI.new)
sleep
_ 6. Rinda and Linda
最後にdRubyを元にしたLindaの実装、Rindaと、その応用事例を紹介する。
Lindaは分散協調システムの糊言語のコンセプトである。タプルとタプルスペースというシンプルなモデルによって複数のタスクを協調させることができる。シンプルでありながら並列プログラミングにおいて出会うさまざまな状況に対応できる魅力的なモデルである。このため、さまざまな言語に、その言語らしいタプルスペースの実装が存在する。
C-LindaやJavaSpace、Rindaは代表的な実装例である。
Finally, I shall introduce Linda's implementations based on dRuby, Rinda and its practical use case.
Linda is a concept of a glue language in the distributed coordination system. A simple model of tuples and tuple spaces enables to coordinate multiple tasks. That is to say, it is very attracting model that can manage various situations caused due to a parallel programming, even though it is a simple. Because of this reason behind, many languages incorporate the tuple spaces of its own.
C-Linda, JavaSpace and Rinda are typical examples of the implementation seen from the following.
C-Lindaはベースの言語(C)を拡張し、Lindaの操作を追加するもので、プリプロセッサによって実現されている。またJavaSpaceはJavaにおけるタプルスペースの実装である。
そして、Rubyのタプルスペースの実装はRindaである。RindaはLindaのタプルとタプルスペースのモデルをRubyに実装したものだ。
C-Linda enhances a base language(C)and adds Linda's operations, so these are achieved by executing preprocessors. Regarding the implementations of JavaSpace, the tuple space is implemented by using Java. The implementations of Ruby's tuple space are achieved in Rinda. That is, Rinda implemented Linda's tuple and tuple space model in Ruby.
C-Lindaでは操作対象のタプルスペースは暗黙的に決められたただ一つで、タプルスペースを指定する必要はない。これに対し、Rindaではタプルスペース・オブジェクトへのメッセージ送信でおこなう。つまりRindaではどのタプルスペースを利用するか、アプリケーションが気をつける必要がある。
In the case of C-Linda, operable tuple spaces are implicitly limited to one tuple space, so that the tuple space does not have to be specified. In another case of Rinda, as tuple space and objects are communicated by message, applications have to decide which tuple spaces will use.
Rindaでは、Lindaの基本操作のうち、evalを除いたout, in, inp, rd, rdpが利用できる。Rindaにはevalは用意されないが、おそらくRubyスレッドで代用できるであろう。
In the case of Rinda, in the Linda's basic operations, out, in, inp, rd, rdp except for eval are available, but that can be substituted for Ruby' threads.
Rindaの最近のバージョンでは、基本操作のメソッド名がJavaSpace風に変更された。
Latest version of Rinda changed the basic operation method names to that like JavaSpace.
- write
- タプルをタプルスペースに追加する (out)
- take
- マッチしたタプルをタペルスペースから削除し、削除したタプルを返す。マッチするタプルがなければブロックする。 (in)。
- read
- マッチしたタプルのコピーを返す。マッチするタプルがなければブロックする (rd)。
- write
- Add tuples to tuple space. (out)
- take
- Delete matching tuples from the tuple space, and return the deleted tuples. If a matching tuples do not exist, block them. (in)
- read
- Return copy of matching tuples. If matching tuples do not exist, block them. (rd)
takeとreadはタイムアウト時間を設定できる。タイムアウト時間に0を設定することで、inp, rdpと同様に動作する。
これら基本操作の他に、パターンにマッチするタプルを全て読み出すread_allも用意されてる。これは主にデバッグなどで活躍すると思われる。
Take and read is used to set timeout. If the timeout sets to zero, they behave similar to inp, rdp.
Apart from these basic operations, read_all is also available to read all tuples matching to patterns. The read_all appears to be useful for a debug use.
タプルとパターンはRubyのArrayを用いて表現する。また、タプルのパターンマッチングの規則はRuby風に拡張され、ワイルドカード(Rindaではnilがワイルドカードとなる)の他に、クラス、さらにRange、Regexpなどを指定でき、ちょっとした問い合わせ言語のような使い方が可能である。
The tuple and patterns are expressed by Array of Ruby. Regulations of matching tuple patterns are expanded to Ruby-like regulations, so that not only wild card(Wild card in Rinda means nil.) but also classes, further more Range and Regexp can be specified. Rinda can be handled like a sort of query language.
また、これは実験的な機能と言えるが、タプルに「期限」を設定することも可能である。期限は秒を意味する数値を指定することもできるほか、「期限更新オブジェクト(Rindaではrenewerと呼ぶ)」を指定することもできる。期限の更新をするかどうか、オブジェクトに尋ねるのだ。renewerとしてdRubyの参照を与えることも可能であるので、たとえば、タプルの生成者が異常終了してしばらくすると期限切れになるタプルを実現することができる。
Furthermore, “time limit” can set in the tuples, though this function is still under experiment. Also, numbers indicating seconds and “time line update objects (It is called renewer in Rinda.)” can be specified in the time limit. Whether to renew the time line or not is enquired to the objects. Rinda can also give dRuby's reference as renewer.. For instance, a tuple creator is closed abnormally. After some time, tuples to turn to out of time limit can be provided.
6.1. Dining philosophers
Rindaの節も実際のコードを追いながら説明しよう。
In terms of Rinda, I explain to you with actual code.
require 'rinda/tuplespace' # (1)
class Phil
def initialize(ts, num, size) # (2)
@ts = ts
@left = num
@right = (@left + 1) % size
@status = ' '
end
attr_reader :status
def think
@status = 'T'
sleep(rand)
@status = '_'
end
def eat
@status = 'E'
sleep(rand)
@status = '.'
end
def main_loop # (3)
while true
think
@ts.take([:room_ticket])
@ts.take([:chopstick, @left])
@ts.take([:chopstick, @right])
eat
@ts.write([:chopstick, @left])
@ts.write([:chopstick, @right])
@ts.write([:room_ticket])
end
end
end
ts = Rinda::TupleSpace.new # (4)
size = 10
phil = []
size.times do |n|
phil[n] = Phil.new(ts, n, size)
Thread.start(n) do |x| # (5)
phil[x].main_loop
end
ts.write([:chopstick, n])
end
(size - 1).times do
ts.write([:room_ticket])
end
while true # (6)
sleep 0.3
puts phil.collect {|x| x.status}.join(" ")
end
紹介するのは馴染み深い「哲学者の食事問題」である。
このプログラムは二種類のタプルを用いる。一つはchopstick、もう一つはroom ticketである。chopstickは2要素のタプルで、第一要素はシンボル「:chopstick」、第二要素は箸の番号を示す整数である。room_ticketは部屋に入れる哲学者の人数を制約するためのチケットで、要素はシンボル「:room_ticket」の一つだけを持つタプルである。
A well- known “dining philosophers” is introduced here.
This program uses two types of tuples. One is chopstick, and another is room ticket.
Chopstick has a tuple with two elements. The first element is symbol “:chopstick”, and the second element is an integer indicating the chopstick's number. room_ticket is a ticket that limits the number of philosophers to let in the room. The element contains just a symble “:room_ticket”.
Philクラスは哲学者をあらわすクラスである。
Philオブジェクトはタプルスペース、番号、テーブルの座席数とともに生成される。哲学者の様子を観察するために必要な、状態を示すインスタンス変数を持つ(2)。
操作対象のタプルスペースを渡す(知っている)必要があるところが、C-Lindaと異なる。
Philクラスのmain_loopメソッドは哲学者の行動をあらわす無限ループだ(3)。main_loopは、think()した後、食事のためにroom_ticketの取得、左のchopstickの取得、右のchopstickの取得を行なう。全て揃ったらeat()を行う。食事が終ると左右のchopstickとroom_ticketをタプルスペースに戻し、再び思索に耽る。
Phil class indicates a philosopher.
The Phil object is generated along with tuple spaces, numbers, and number of seats of the table. The object has instance variables indicating status(2). These variables are required to monitor philosopher's status.
Compared to C-Linda, Rinda has to pass target tuple spaces.
main_loop method in the Phil class is an infinite loop indicating philosopher's actions(3). After executing think(), the main_loop gets room_ticket for dining, and get a left chopstick and following right chopstick. Once all items are ready, execute eat(). When the dining finishes, return the left and right chopsticks and the room_ticket to the tuple space, and again return to think().
メインプログラムでは、まずタプルスペースを生成する(4)。そして哲学者たちを生成し、サブスレッドでmain_loopメソッドを起動する(5)。これはC-Lindaでいうところのeval()操作に近いものである。そして、人数分のchopstickと、一つ少ないroom_ticketをタプルスペースにwriteする。
In the main program, firstly create tuple spaces (4), and create philosophers, and then invoke the main_loop method by subthread(5). These operations are similar to eval() operation in C-Linda. Chopsticks corresponding to number of people and room_ticket of 1 lower number are written to the tuple spaces.
最後の無限ループは、哲学者たちの様子を0.3秒置きに観察するループである(6)。哲学者がその瞬間に、考えているのか、食事をしているのか、箸を待っているのかといったことを表示するのである。
The last infinite loop is a group to monitor philosophers every 0.3 seconds(6). The loop indicates their actions whether they are thinking, dining, or holding chopsticks e.g. at that moment.
6.2. Tuple and Pattern
Rindaにおけるタプルとパターン、パターンマッチングについて説明する。タプルやパターンがArrayで表現されることはすでに述べたが、要素に特徴がある。要素にはdRubyの参照を含む、全てのRubyオブジェクトが指定可能である。
Here, I explain tuples and patterns and pattern matching in Rinda. As I mentioned before, those tuples and the patterns are expressed in Array. There are characteristics in elements. For the elements, all Ruby objects including dRuby's reference can be specified.
[:chopstick, 2] [:room_ticket] ['abc', 2, 5] [:matrix, 1.6, 3.14] ['family', 'is-sister', 'Carolyn', 'Elinor']
パターンも同様に全てのRubyオブジェクトを要素に持つことができる。少し変わっているのはパターンマッチングの規則である。nilは全てあらゆるオブジェクトとマッチするワイルドカードとして解釈される。そして、それぞれの要素は「===(case equals)」による比較を行なう。
Similarly for patterns, all Ruby's objects are available as elements. In terms of pattern matching, its regulations are a little strange. nil is interpreted as wild card which can match any objects and each element is compared by “===(case equals)”.
Rubyにはcase式というCのswitchのような分岐がある。そして、「===(case equals)」はそのcase式で用いられる特別な同値判定である。「===」は基本的に「==」と同じであるが、一部のクラスで「パターン風」な振舞いをする。
たとえば、Regexpは文字列のパターンマッチとなり、Rangeは値がその範囲に入っているかの検査となる。パターンの要素にClassを指定した場合ではkind_of()の判定になるので、クラスを指定したパターンも記述できる。
Ruby has a case expression and the case expression is a branch just like c switch. “===(case equals)” is special equality comparisons. “===” is basically similar to “==”, however, in a certain class, it behaves “like patterns”.
For example, Regexp is nothing but a pattern matching of strings, and Range identifies whether values are within the limited range or not. When a Class is specified as pattern elements, it has come to be justified by kind_of(), so that patterns with class-specified can be described as well.
パターンの例を示す。
The followings are given sample examples of the patterns.
[/^A/, nil, nil] (1)
[:matrix, Numeric, Numeric] (2)
['family', 'is-sister', 'Carolyn', nil] (3)
[nil, 'age', (0..18)] (4)
- 最初の要素がAで始まる文字列の三要素のタプル
- 最初の要素がシンボル:matrixで、2, 3要素が数値クラスのタプル
- Carolynの姉妹のタプル
- 年齢が0から18のタプル
[/^A/, nil, nil] (1) [:matrix, Numeric, Numeric] (2) ['family', 'is-sister', 'Carolyn', nil] (3) [nil, 'age', (0..18)] (4)
- A tuple made of three elements, and the first element starts with "A"-string
- A tuple arranged by that the first element is symbol "matrix" and the second and the third element are a numeric class.
- Tuple of Carolyn sister
- Tuple aged from 0 to 18
共有のTupleSpaceサーバと対話環境irbを使ってパターンマッチングのようすを確認しよう。
Let's check that patterns are matching by using shared TupleSpace server and interactive environment irb.
require 'rinda/tuplespace'
ts = Rinda::TupleSpace.new
DRb.start_service('druby://localhost:12121', ts)
sleep
この4行が共有TupleSpaceのスクリプトだ。
This 4 lines are the script of shared TupleSpace.
% irb --simple-prompt -r rinda/rinda
>> DRb.start_service
>> ro = DRbObject.new_with_uri('druby://localhost:12121')
>> ts = Rinda::TupleSpaceProxy.new(ro)
>> ts.write(['seki', 'age', 20])
>> ts.write(['sougo', 'age', 18])
>> ts.write(['leonard', 'age', 18])
>> ts.read_all([nil, 'age', 0..19])
=> [["sougo", "age", 18], ["leonard", "age", 18]]
>> ts.read_all([/^s/, 'age', nil])
=> [["seki", "age", 20], ["sougo", "age", 18]]
>> exit
Ruby風で柔軟なパターンが使えることがわかる。
タプルスペースを簡単なデータベースとして使うことができると思うかもしれないが、しかし、大量のタプルを扱う場合には注意が必要である。なぜなら、Rindaはこの柔軟なパターンのAPIの性質上、タプルスペースを線形に探索してしまうのだ。
You can see that Ruby-like flexible patterns are available.
You might also consider that tuple spaces can be used as a simple data base. In this point, you have to be careful in dealing with a large number of tuples, according to the nature of API with the pattern-flexible, Rinda conducts a liner search.
6.3. Unfair optimization
なお、現在のRindaは一般的な(typicalな?)アプリケーションで高速に検索ができるように、不公平な最適化を導入した。先頭の要素がシンボルである場合に限り、専用のコレクションにタプルを格納する。
経験上、次のような形式のタプルを使うアプリケーションが多い。
Latest Rinda has already implemented unfair optimization in order to perform searchings at a high speed by using general applications. Only when the first element is a symbol, store tuples to an own collection.
As per my experience, the following type of tuples is often used by application side.
[:screenshot, 12345, "http://www.druby.org"] [:result_screenshot, 12345, true] [:prime, 10]
つまり、メッセージ種といくつかの引数からなるタプルである。そしてtakeやreadでは次のようなパターンを用いる。
That is to say, it is tuples composed of a type of message and some arguments. In the case of take or read, the following pattern is applicable.
[:screenshot, nil, String] [:result_screenshot, 12345, nil] [:prime, Numeric]
特定のメッセージ種のタプルのうち、どれか一つを取り出すパターンだ。
この状況を踏まえると、先頭の要素をキーとして、それぞれ専用のコレクションに格納して、検索する対象を絞ることで、高速化が期待できると考えられる。ここで一つ問題がある。どんなオブジェクトでもキーとして高速化が期待できるかどうかだ。Rindaのパターンでは「===(case match)」を用いるので、StringやIntegerはキーとして適さないのだ。しかしながら、Symbolは「===(case match)」するパターンはSymbolクラスとそのSymbol値のみであるため、キーとして最適である。その上、SymbolはStringと同じくらいに読みやすい。
This is nothing but a pattern which takes any one from a certain message type tuples.
Considering this situation, you can probably expect high performance by storing the first element as a key into own collection and focusing on search targets. On the other hand, there is another problem whether or not any objects can be used as a key to achieve a high performance. In the case of Rinda's pattern, the use of“===(case match)” comes to unsuitable for String and Integer as a key.
However, Symbol is still appropriate as a key because “===(case match)” of Symbol has a Symbol class and its values only. Furthermore, Symbol is as easy to read as String.
不公平な最適化についてもう一度まとめよう。最新版のRindaではタプルの先頭の要素がa Symbolである場合、不公平な最適化を行ない、take/readが速くなる。また、take/readにおいても同様に、先頭の要素がa Symbolであるパターンの検索は高速になる。
Let's summarize the unfair optimization here. In the latest Rinda, when the first element in the tuple is a Symbol, Rinda executes the unfair optimization, and performance on take/read is improved. Similarly for take/read, when a pattern search is that the first element is a Symbol, the searching performance comes faster than usual.
6.4. Application of Rinda
実世界でのRindaの応用例を紹介する。Buzztterは、短文に特化したSNSであるTwitterの文章を解釈するWebサービスである。BuzztterはTwitterに投稿される文章を集めて解釈し、普段よりも多く言及されている言葉を見つけ出すことで、Twitter全体のいまこの瞬間の動向を推測する。
Here, I introduce a practical use of Rinda. Buzztter is a Web service interpreting Twitter sentences. The Twitter is SNS specialized on a short sentence. Buzztter collects posted sentences into Twitter, and interpret the sentences, and figure out words more often used than usual. By doing so, Buzztter understands overall trends of words of that moment in the Twitter.
Buzztterはいくつかのサブシステムで構成される。Rindaを利用しているのは、Twitter API (HTTP)を用いて文章を集めてくる分散クローラサブシステムである。このサブシステムはTwitterから情報をフェッチする複数のfetcherと、永続化を行うimporterによって構成される。fetcherとimporterの間を取り持つのがRindaとdRubyである。
参考にBuzztterが扱うデータ量を挙げる(2007-11-3調べ)。
- 125000件/日
- 72MB/日
Buzztter composes of several subsystems, in which a distributed crawler subsystem; a subsystem collects sentences by using Twitter API(HTTP); uses Rinda. The crawler subsystem is made of multiple fetchers that is to fetch information from Twitter and importers that is to make it persistent. Rinda and dRuby is a mediator between the fetchers and the importers.
For your reference, the following is the data to be handled by Buzztter (as of Nov 3, 2007)
- 125000 case per day
- 72MB per day
6.5. Rinda Update
最後にRindaの最新動向を述べる。昨年、RubyKaigi 2007において永続的なTupleSpaceのリリースについてアナウンスした。Rinda::TupleSpaceの内容はそのプロセスが終了すると消えてしまうが、永続版TupleSpaceはプロセス再起動時に直線のタプルスペースを復元する。実行中は再起動に備えてロギングし、再起動時にはログを手がかりにタプルスペースを再構築する。なお、実行中はストレージの内容を読まず、ログを書くだけである。
Lastly, I discuss Rinda's latest trends. Last year, in RubyKaigi 2007, persistent TupleSpace release was announced. Information of Rinda::TupleSpace disappears once processes finish. The persistent TupleSpace recovers a straight tuple space at the time of invoking processes again. During the execution, in order to be ready for re-invocation, the persistent TupleSpace keeps logging. At the time of invoking again, referring log information, the TupleSpace rebuilds the processes. While executing, the TupleSpace just keep logging, but it does mean to read contents in the storage.
_ 7. Conclusion
dRubyの概念から設計ポリシーと実装について説明し、実世界で応用例を紹介した。
またdRubyをベースに開発されたタプルスペースの実装、Rindaについても述べた。
dRubyもRindaも、Rubyプログラマにとって馴染み易いシンプルなシステムとして設計されており、分散システムのスケッチに最適である。しかしながら、多くの実世界の応用例は、dRubyおよびRindaがスケッチ専用の「おもちゃ(toy)」ではなく、実世界のアプリケーションを構築するインフラとして利用できることを示している。
I discussed dRuby's design policy and the implementations along with its concept, and introduced the practical usage. In addition to that, I discussed implementations of TupleSpace developed based on dRuby and Rinda. Both dRuby and Rinda are designed as a simple system in order for Ruby programmers to feel comfortable to know more of it. Hence, this is most appropriate to sketch the distributed system. However, practical examples discussed in this article are not for a “toy” discussion for sketching purpose. Those examples well demonstrated that dRuby and Rinda are practically available as infrastructure to build practical applications.
*1: http://www.slideshare.net/Blaine/scaling-twitter/
*2: http://www.slideshare.net/Blaine/scaling-twitter/
*3: http://blade.nagaokaut.ac.jp/cgi-bin/scat.rb/ruby/ruby-list/15406
*4: http://blade.nagaokaut.ac.jp/cgi-bin/scat.rb/ruby/ruby-list/15406
*5: なお、ネットワークやメッセージ形式はカスタマイズ可能である。
*6: The network and the message format can be customized.