




5 pass by reference, pass by value
この章では、二つのオブジェクトの交換方法、参照渡しと値渡しについて説明します。
5.1 参照渡しと値渡し(pass by reference, pass by value)
dRubyではメソッド呼び出しの引数や、メソッドの戻り値として プロセスとプロセスの間でオブジェクトがやりとりされます。 このときの渡し方には、オブジェクトのコピーを渡す方式と オブジェクトの参照情報を渡す方式の二つがあります。
この節では参照渡しと値渡しの違いと、dRubyでの渡し方の コントロールについて説明します。
5.1.1 Rubyではどうなる?
「参照渡し」はいつものRubyスクリプトで行なっている交換方法です。 irbでちょっと実験してみましょう。
% irb --prompt simple >> def foo(str); str.chop!; end >> my_str = "Hello, World." >> foo(my_str) >> my_str => "Hello, World" >> foo(my_str) >> my_str => "Hello, Worl"
文字列の末尾を削除するchop!を呼ぶだけのメソッドfooを定義します。 変数my_strに文字列"Hello, World."をセットしfooを繰り返し 呼び出すとmy_strの指すStringが短くなっていきます。 fooメソッドで行なったchop!が元の文字列に影響したのです。
ではオブジェクトのコピーを渡す「値渡し」はどうでしょう。 「値渡し」をirbで実験してみましょう。
>> my_str = "Hello, World." >> foo(my_str.dup) => "Hello, World" >> my_str => "Hello, World." >> foo(my_str.dup) => "Hello, World" >> my_str => "Hello, World."
メソッド呼び出しのパラメータにオブジェクトの複製を与えると、 「値渡し」となります。my_strの複製をfooメソッドに 渡すので、my_strはずっと"Hello, World."のままです。 fooメソッドでの操作が元の文字列にはなんら影響がないことがわかります。
Rubyのメソッド呼び出しではいつも「参照渡し(pass by reference)」です。 「値渡し(pass by value)」にするために、dupなどの明示的な操作が必要と なります。
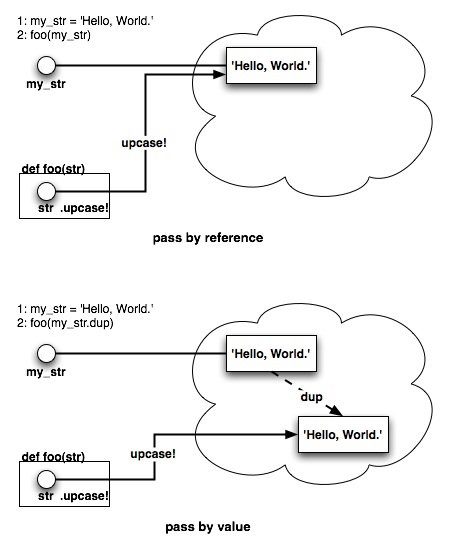
図5.1 いつもの参照渡しと、明示的な値渡し
5.1.2 dRubyでは?
Marshal
dRubyではRubyのクラスライブラリMarshalを用いて 他のプロセスにオブジェクトを渡します。 Marshalは任意のオブジェクトをバイト列に直列化するdumpメソッドと、 直列化されたバイト列からオブジェクトを再現するloadメソッドからなります。 MarshalはRubyでdeep copy(深いコピー)を行うのにも利用できます。
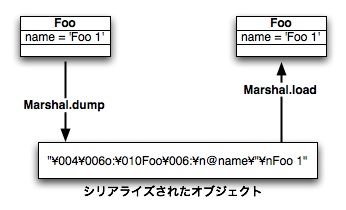
図5.2 オブジェクトをMarshalして複製する
Marshalをちょっと実験してみましょう。
[ターミナル1] % irb --prompt simple >> class Foo >> attr_accessor :name >> end >> it = Foo.new >> it.name = 'Foo 1' >> it => #<Foo:0x40200e34 @name="Foo 1"> >> str = Marshal.dump(it) => "?004?006o:?010Foo?006:?n@name?"?nFoo 1" # ←これが直列化したバイト列 >> foo = Marshal.load(str) => #<Foo:0x401f4008 @name="Foo 1"> # itとはidの違う同じオブジェクトができた!
さらにもう一つのターミナルで似たようなことをしてみます。 先ほどのMarshal.dumpの結果をコピーして使用します。
[ターミナル2] % irb --prompt simple >> class Foo # ターミナル2のirbでもクラスFooの定義をする >> attr_accessor :name >> end >> str = "?004?006o:?010Foo?006:?n@name?"?nFoo 1" # 先ほどのdumpの結果をコピー/ペースト >> Marshal.load(str) => #<Foo:0x4021c0a8 @name="Foo 1"> # Fooオブジェクトの複製が!
どうですか?ターミナル1でMarshal.dumpしたバイト列(文字列)を使って ターミナル2でMarshal.loadできましたか?
参照の値渡し
この実験ではターミナルソフトのコピー/ペーストを用いてバイト列を交換しましたが、 これをソケットで行うことでプロセス(そしてマシン)を越えてオブジェクトを 交換できるのです。dRubyはこのMarshalを使って他のプロセスのオブジェクトの メソッドを呼出し、引数のオブジェクトを与え、戻り値を受け取るのです。
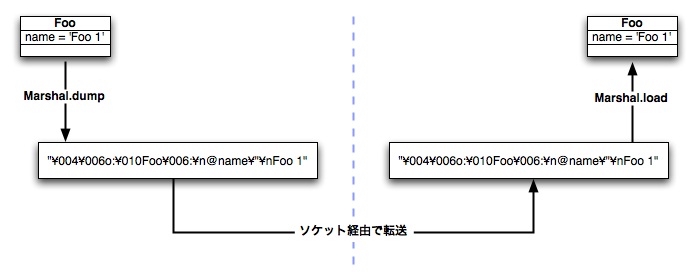
図5.3 オブジェクトをMarshalしてソケット経由で転送する
Marshal.loadによって直列化したオブジェクトをMarshal.dumpで復元するということは、 つまりオブジェクトの複製を作ることにほかなりません。 ではdRubyはいつも値渡しなのでしょうか?
実は当たっているとも言えるし違うとも言えます。 dRubyでの参照渡しは、元のオブジェクトの代わりに参照情報を含むオブジェクトを 直列化することで実現されます。つまり、参照渡しは参照オブジェクトの値渡しなのです。 逆に、もう一方の値渡しは単純にオブジェクトを直列化するだけです。
Hello, World.の実験で使ったDRbObjectを覚えていますか? DRbObjectは元のオブジェクトを参照する情報をもったオブジェクトです。 DRbObjectには目的にごとに二つの生成方法が用意されています。 一つはDRbObject.new_with_uriを使ってURIからリモートオブジェクトへの 参照を作ることです。*1 もう一つはDRbObject.new(obj)のようにオブジェクトを与え 自プロセスのオブジェクトへの参照を作ることです。
% irb --prompt simple -r drb/drb >> DRb.start_service # オブジェクトからDRbObjectを作るには、自分のプロセスにサーバが必要 >> ary = [1, 2, 3] [1, 2, 3] >> ref = DRbObject.new(ary) => #<DRb::DRbObject:0x401eb2b4 @ref=537879846, @uri="druby://yourhost:41708">
DRbObject.new(obj)によって、任意のオブジェクトへの参照オブジェクトを作ります。 参照を作るということは、他のプロセスがこの参照をつかってメソッド呼び出しする 可能性があるということです。ですから、 オブジェクトへの参照を作る前に、DRb.start_serviceによってdRubyのサーバを 自プロセスで起動しておかなくてはなりません。 DRb.start_serviceによって自プロセスの(つまりDRbServerの)URIが決まります。
DRbObjectのinspectの結果を観察してみましょう。
>> ref => #<DRb::DRbObject:0x401eb2b4 @ref=537879846, @uri="druby://yourhost:41708">
DRbObjectには二つのインスタンス変数があります。 ひとつは@uriで自プロセスのURI、もうひとつはオブジェクトの識別情報です。 デフォルトの識別情報は __id__ メソッドの値を利用しています。
>> ary.__id__ => 537879846 >> exit
この実験は終りです。
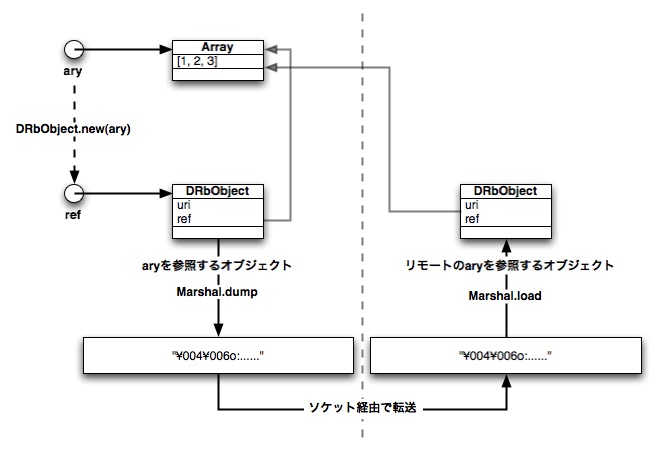
図5.4 参照渡しは参照の値渡しで実装される
次はオブジェクトのキャッチボールです。 まずはHashをフロントオブジェクトにしてDRb.start_serviceします。 このサービスのURIはfrontが指しているHashと関連づけられます。
このプロセスは任意のオブジェクトを保持できるサーバだと考えることができます。
[ターミナル1]
% irb --prompt simple -r drb/drb
>> front = {}
>> DRb.start_service(nil, front)
=> #<DRb::DRbServer:0x ..... >
>> DRb.uri
=> "druby://yourhost:1426"
ターミナル1のサービスのURIは'druby://yorurhost:1426'です。 これを使ってターミナル2からアクセスします。 ターミナル2でもサービスを起動します。
[ターミナル2]
% irb --prompt simple -r drb/drb
>> DRb.start_service
>> there = DRbObject.new_with_uri("druby://yourhost:1426")
=> #<DRb::DRbObject:0x2ac5fe94 @uri="druby://yourhost:1426", @ref=nil>
URIを与えて参照を作ります。 DRbServerを特定する@uriは"druby://yourhost:1426"、 識別情報@ref=nilです。@refがnilの場合は特別にURIに関連づけられた フロントオブジェクトを参照します。
ではthereのキー「1」に"Hello, World."をセットしてみましょう。
[ターミナル2] >> str = "Hello, World." >> there[1] = str => "Hello, World."
ターミナル1のfrontがどうなったのか調べてみます。
[ターミナル1]
>> front
=> {1=>"Hello, World."}
おおっ。 なんとfrontオブジェクトに"Hello, World."が入っています。
ターミナル2のStringのオブジェクト"Hello, World."は、 dRubyライブラリによりバイト列として転送され、 ターミナル1のdRubyライブラリで復元されました。 "Hello, World."はおそらく値渡しによって交換されたはずです。
本当に値渡しだったのでしょうか。実験してみましょう。 まず、元の文字列を破壊的に置換します。 操作の前後でstrのオブジェクトのidを比べてオブジェクトが同じものであることも 確認します。
[ターミナル2] >> str.__id__ => 358800978 >> str.sub!(/World/, 'dRuby') => "Hello, dRuby." # 破壊的な置換 >> str.__id__ => 358800978 # ← Stringオブジェクトが同じものであることを確認してください
破壊的な置換がターミナル1のオブジェクトに影響したでしょうか?
[ターミナル1]
>> front
=> {1=>"Hello, World."}
OK。フロントオブジェクトが保持している文字列は"Hello, World."のままです。 ターミナル2での破壊的な置換の影響はありませんでした。
せっかくなのでターミナル1の"Hello, World"も変更してみます。
[ターミナル1] >> front[1].sub!(/World/, 'Ruby') => "Hello, Ruby." >> puts front[1] Hello, Ruby. => nil [ターミナル2] >> str => "Hello, dRuby."
やはり影響がありません。安心しました。
次に明示的な参照渡しを試します。 明示的な参照オブジェクト(DRbObject)の生成はDRbObject.new()を使います。 strの指すオブジェクトへの参照を明示的に生成して、 thereのキー「2」にセットしてます。
[ターミナル2] >> there[2] = DRbObject.new(str) => "Hello, dRuby."
ではfrontの中身を覗いてみましょう。
[ターミナル1]
>> front
=> {1=>"Hello, Ruby.", 2=>#<DRb::DRbObject:...>}
front[2]はDRbObjectになっているのがわかりますね。 印字するとどうなるでしょう。
>> puts front[1] Hello, Ruby. => nil >> puts front[2] Hello, dRuby. => nil
front[2]はDRbObject、つまり参照、ですが、putsすると"Hello, dRuby."と なりました。
なにが起きたのでしょう? putsは引数のオブジェクトのto_sを呼び出した結果を印字するメソッドなので、 まずはじめに front[2].to_s が 呼ばれ、次にその結果を印字したのです。 DRbObjectのメソッド呼び出しはそのまま元のオブジェクト、 つまりターミナル2の"Hello, dRuby."に転送されます。 図のような流れです。
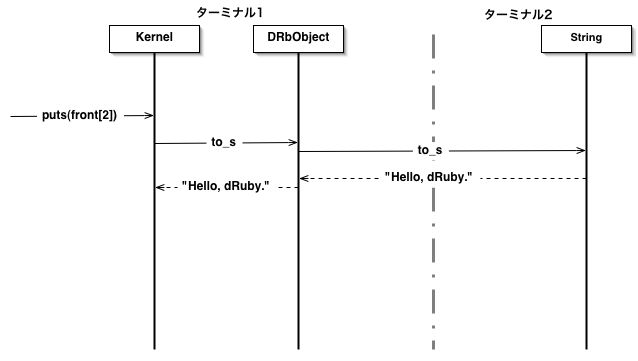
図5.5 ターミナル1からターミナル2のオブジェクトのメソッドを呼び出す。
[ターミナル1] >> front[2].to_s => "Hello, dRuby."
次にターミナル2の"Hello, dRuby."への操作が ちゃんとターミナル1に影響するかどうか確認しましょう。
[ターミナル2] >> str.sub!(/dRuby/, 'Ruby and dRuby') => "Hello, Ruby and dRuby." [ターミナル1] >> front[2].to_s => "Hello, Ruby and dRuby."
お!ターミナル2のstr.sub!の結果がターミナル1に影響されてます。 いつものRubyのように参照渡しになったのです。
そうなると、 ターミナル1から文字列が変更できるかどうかもやってみたいですよね?
[ターミナル1] >> front[2].sub!(/Ruby and dRuby/, 'World') => "Hello, World." [ターミナル2] >> str => "Hello, World."
期待した通り、 ターミナル1からのfront[2].sub!()によって、ターミナル2の文字列を変更することが できました。
この節では明示的な参照渡しの実験をしてみました。 でも実験はまだ続きます。 二つのターミナルのirbはまだ閉じないで!
5.1.3 どちらがサーバでどちらがクライアント?
そう言えば‥ front[2].sub!()は、ターミナル2のオブジェクトのメソッド呼び出しですね。 いったいどちらがサーバでどちらがクライアントでしょうか?
dRubyのレベルでメソッド呼び出しを観察すると、 メソッド呼び出しのレシーバ側がサーバでセンダーがクライアントと言えます。
there[1] = "Hello, World."
では、thereの[]=(key, value)メソッドが呼び出されました。 このとき、thereが本当にあるところ、つまりターミナル1の方のirbがサーバで、 このメソッドを呼び出したセンダー(ターミナル2)がクライアントです。
front[2].sub!
ターミナル1での上の式では、レシーバはfront[2]の文字列の本当に存在する ターミナル2のirbがサーバで、ターミナル1がクライアントです。
dRubyに参加するプロセスは、どのプロセスもサーバにもクライアントにもなります。
ターミナル2のirbを終了させてから、もう一度front[2].sub!を呼んでみましょう。 front[2]のオブジェクトが本当に存在するのはターミナル2のirbです。 終了させてからメソッドを呼び出したら何が起こると思いますか?
[ターミナル2]
>> exit
[ターミナル1]
>> front[2].sub!(/Hello/, 'Goodbye')
DRb::DRbConnError: druby://yourhost:1428 - #<Errno::ECONNREFUSED: 接続を拒否されました - "connect(2)">
from /usr/local/lib/ruby/site_ruby/1.6/drb/drb.rb:170:in `open'
from /usr/local/lib/ruby/site_ruby/1.6/drb/drb.rb:163:in `each'
....
そうそう。やっぱり失敗です。想像した通りでしょ?
この節のメモ。
- dRubyではどのスクリプトも簡単にサーバになれます。
- それにどのスクリプトもサーバであったり、クライアントであったりします。
- その関係はメソッド呼び出しのレシーバ、センダーの関係と同じです。
5.2 自動的な参照渡し
参照渡しにするには、いつも明示的にDRbObject.new()しなくては ならないのでしょうか? なんだか面倒ですね。 dRubyでは明示的に参照渡しをしなくても、ライブラリが自動的に判断して 参照渡しと値渡しを選択する仕組みが用意されています。
dRubyでは次の規則で参照渡しと値渡しを選択します。
- Marshal.dumpできるものは値渡し
- Marshal.dumpできないものは参照渡し
簡単でしょう? 実験しながら動作を確認していきましょう。
5.2.1 can't dump
Marshalにはdumpすることが可能なオブジェクトと不可能なオブジェクトがあります。 たとえばIOやThread、Procはdumpできません。
標準出力($stdout)をdumpするとどうなるでしょう。
% irb --prompt simple >> Marshal.dump($stdout) TypeError: can't dump IO ...
この通りTypeError例外が発生します。 $stdoutはIOのインスタンスで、dumpすることができないオブジェクトなのです。 Marshal.dumpはそのオブジェクトがdump可能でもdumpできないオブジェクトを 参照しているときにも失敗します。
>> ary = [] => [] >> Marshal.dump(ary) => "?004 ...." >> ary[0] = $stdout => #<IO:0x ..... > >> Marshal.dump(ary) TypeError: can't dump IO ...
では$stdoutをdRubyで別プロセスに渡したらどうなるでしょうか? ターミナルを二つ用意して実験します。
[ターミナル1]
% irb --prompt simple -r drb/drb
>> front = {}
>> DRb.start_service('druby://yourhost:12345', front)
=> #<DRb::DRbServer:0x ..... >
>> DRb.uri
=> "druby://yourhost:12345"
先ほどと同様にHashをfrontにしたサーバを起動します。
[ターミナル2]
% irb --prompt simple -r drb/drb
>> DRb.start_service
=> #<DRb::DRbServer:0x ..... >
>> DRb.uri
=> "druby://yourhost:1121"
>> there = DRbObject.new_with_uri('druby://yourhost:12345')
=> #<DRb::DRbObject:0x ..... >
クライアントも準備できました。 では$stdoutをターミナル1に渡してみましょう。
[ターミナル2] >> there[:stdout] = $stdout => #<IO:0x ..... >
Marshal.dumpに失敗したはずですが、特にエラーになりませんでした。 渡した$stdoutがどうなったのか、ターミナル1を確認しましょう。
[ターミナル1] >> front[:stdout] => #<DRb::DRbObject:0x ..... @uri="druby://yourhost:1121", @ref= ..... >
front[:stdout]はIOではなく、DRbObjectとなりました。 DRbObjectの@uriはターミナル2のDRb.uriです。 front[:stdout]のDRbObjectはターミナル2のオブジェクトを参照する オブジェクトであることがわかります。
何がおきたのでしょうか? ターミナル2から$stdoutをターミナル1に渡す時、 dRubyのライブラリはMarshal.dumpが失敗したことを捉えて 値渡しの代わりに参照渡しを行なったのです。
本当にターミナル2の$stdoutへの参照が渡っているのか、 ターミナル1からfront[:stdout]に文字列を印字させて確かめましょう。 ターミナル2に出力されるはずですよね?
[ターミナル1]
>> front[:stdout].puts("Hello, DRbObject")
[ターミナル2]
>> Hello, DRbObject
期待通り"Hello, DRbObject"がターミナル2に出力されました。 front[:stdout]はターミナル2の$stdoutだったのです。よかった。
Marshal.dumpができないオブジェクトを送り出すときに自動的に 参照渡しにする動きが確認できたでしょうか? dRubyでは明示的に参照渡しを指示する必要がないのです。
また、dRubyでは自分の管理するオブジェクトへの参照を受けとると、 参照されているオブジェクトを受けとったように振舞います。 ターミナル2で、さきほどの$stdoutの参照を取り出してみましょう。
[ターミナル2] >> there[:stdout] => #<IO:0x ..... >
DRbObjectではなくIOのインスタンスとなりました。 これは$stdoutと同じものです。
[ターミナル2] >> there[:stdout] == $stdout => true
5.2.2 DRbUndumped
Marshal.dumpできないオブジェクトが自動的に参照渡しとなることを確認しました。 IOやThread、Procは自動的に参照渡しとなります。
しばしば自分の定義したクラスを参照渡しにしたいことがあります。 dumpできないオブジェクトを含まない場合は、値渡しとなってしまうので あちこちに明示的な参照渡しを書く必要がでてきます。
そこで、いつも参照渡しとなるように、Marshal.dumpを失敗させるための Mixinモジュール DRbUndumped を用意しています。
DRb::DRbUndumped(別名DRbUndumpedも使えます)は、クラスにincludeしたり オブジェクトにextendして使用するモジュールです。
実験してみましょう。
簡単なクラスFoo(foo.rb)を準備します。
List 5.1 foo.rb
class Foo
def initialize(name)
@name = name
end
attr_accessor :name
end
foo.rbをrequireしてdRubyのサービスを開始します。
[ターミナル1]
% irb --prompt simple -r drb/drb -r foo.rb
>> front = {}
>> DRb.start_service('druby://yourhost:12345', front)
[ターミナル2]
% irb --prompt simple -r drb/drb -r foo.rb
>> DRb.start_service
>> there = DRbObject.new_with_uri('druby://yourhost:12345')
まずFooのインスタンスがMarshal.dumpできることを確認して‥
[ターミナル1]
>> foo = Foo.new('Foo1')
>> Marshal.dump(foo)
=> "?004?006 .... "
>> front[:foo] = foo
=> #<Foo:0x .... >
リモートからfooを取り出してみましょう。 dump可能ですから、値渡しになるはずです。
[ターミナル2] >> there[:foo] => #<Foo:0x .... > >> there[:foo].name => "Foo1"
there[:foo]すると参照ではなくFooのインスタンスとなりました。
[ターミナル2] >> there[:foo].name = 'Foo2' [ターミナル1] >> foo.name 'Foo1'
ターミナル1のfooのコピーなので、ターミナル2で属性を変更しても ターミナル1には影響がありません。
つづいてextendでDRbUndumpedを混ぜます。 fooは参照渡しになるはずです。
[ターミナル1] >> foo.extend(DRbUndumped) >> Marshal.dump(foo) TypeError: can't dump ....
fooの参照するFooのインスタンスにDRbUndumpedを混ぜてMarshal.dumpしました。 このようにdumpに失敗することがわかります。
本当に参照渡しになるでしょうか?
[ターミナル2] >> there[:foo] => #<DRb::DRbObject:0x .... > >> there[:foo].name => "Foo1" >> there[:foo].name = 'Foo2' => "Foo2" >> there[:foo].name => "Foo2" [ターミナル1] >> foo.name => "Foo2"
there[:foo]はFooでなくDRbObjectのインスタンスが返りました。 there[:foo].name= を使って@nameを変更すると、 ターミナル1のfooにも影響しています。 期待通り参照渡しにすることができました。
extendはインスタンス単位での指定でした。 クラスにDRbUndumpedするにはincludeを使います。
もう一度、別のFooのインスタンスがMarshal.dumpできることを確認して…
[ターミナル1]
>> bar = Foo.new('Bar1')
>> Marshal.dump(bar)
=> "?004?006 .... "
includeでDRbUndumpedを混ぜます。
[ターミナル1]
>> class Foo
>> include DRbUndumped
>> end
>> Marshal.dump(bar)
TypeError: can't dump
....
>> Marshal.dump(Foo.new('Foo'))
TypeError: can't dump
....
FooのインスタンスすべてがMarshal.dumpに失敗するようになりました。 Marshal.dumpに失敗するのでFooはいつも参照渡しになります。
[ターミナル1] >> front[:bar] = bar [ターミナル2] >> there[:bar] => #<DRb::DRbObject:0x .... > >> there[:bar].name => "Bar1" >> there[:bar].name = 'Bar2' => "Bar2" >> there[:bar].name => "Bar2" [ターミナル1] >> front[:bar].name => "Bar2"
5.3 未知のオブジェクトとDRbUnknown
Marshal.dumpが可能な場合に値渡しになることを説明しました。 あるスクリプトが、受け取ったオブジェクトのクラスの定義を知らないとき、 どういったことが起こるでしょうか。 この節では、未知のオブジェクトの値渡しについて学びます。 前節のfoo.rbを用いて実験してみましょう。
[ターミナル1]
% irb --prompt simple -r drb/drb
>> front = {}
>> DRb.start_service('druby://yourhost:12345', front)
[ターミナル2]
% irb --prompt simple -r drb/drb -r foo.rb
>> DRb.start_service
>> there = DRbObject.new_with_uri('druby://yourhost:12345')
>> foo = Foo.new('Foo1')
>> there[:foo] = foo
=> #<Foo:0x ..... ">
ターミナル1のirbはクラスFooの定義を知りません。 ターミナル2からfront[:foo]にFooのインスタンスを値渡しでセットしました。 ターミナル1にはいったいどんなオブジェクトが届いたのでしょう?
[ターミナル1] >> front[:foo] => #<DRb::DRbUnknown:0x.... @buf="?004?00.....", @name="Foo">
むむ。front[:foo]はFooのインスタンスではありません。 DRbUnknownというクラスのインスタンスであると表示されました。
DRbUnknownとは知らないクラスをMarshal.loadしてしまったときの 例外を捉え、ロードできなかったオブジェクトの代わりにロードされる オブジェクトです。 DRbUnknownはロードに失敗した原因を、二つ保持しています。 一つはロードに失敗したバッファ、もう一つは定義が不明なクラス名/モジュール名です。
それぞれ次のメソッドで問い合わせることができます。
DRbUnknown#buf-
Marshal.loadに失敗した直列化されたオブジェクトのバッファ。
DRbUnknown#name-
例外のメッセージから調べた、未知のクラス/モジュール名。
DRBUnknown#reload-
もう一度Marshal.loadしてみる
dRubyのライブラリは 知らないクラスを受けとってしまっても、そのバッファを包んだ DRbUnknownオブジェクトを自動的に生成します。 DRbUnknownに対して元のオブジェクトのつもりでメソッドを呼ぶことは できませんが、DRbUnknownを回送することはできます。
ターミナル1のDRbUnknownをターミナル2へ渡してみましょう。
[ターミナル2] >> bar = there[:foo] => #<Foo:0x .... @name="Foo1"> >> foo.__id__ == bar.__id__ => false
DRbUnknownではなく、新しいFooのインスタンスが届きました。 (新しいインスタンスかどうかは__id__を比較して調べています。)
dRubyのライブラリはDRbUnknownをMarshal.loadすると、 そのバッファに対してMarshal.loadを再試行します。 成功すれば、DRbUnknownの代わりに包み込んでいた内側のオブジェクトを 返すのです。
三つめのターミナルを開いて回送してみましょう。
[ターミナル3]
% irb --prompt simple -r drb/drb
>> DRb.start_service
>> there = DRbObject.new_with_uri('druby://yourhost:12345')
>> unknown = there[:foo]
=> #<DRb::DRbUnknown:0x.... @buf="?004?00.....", @name="Foo">
>> unknown.name
=> "Foo"
ターミナル3はまだFooの定義を知らないので、DRbUnknownを受けとりました。 unknown.nameの結果は"Foo"です。 foo.rbをrequireして再試行するとどうなるでしょう。
[ターミナル3] >> unknown.reload => #<DRb::DRbUnknown:0x.... @buf="?004?00.....", @name="Foo"> >> require 'foo' >> unknown.reload => #<Foo:0x .... @name="Foo1">
最初のunkonwn.reloadはDRbUnknownを返しましたが、 require後のunknown.reloadではFooを返しました。 再試行に成功したのです。
もう一度ターミナル1から回送してみましょう。 今度はDRbUnknownではなくFooを受けとるはずです。
[ターミナル3] >> foo = there[:foo] => #<Foo:0x .... @name="Foo1">
よかった! すでにFooの定義を知っているので、Fooのインスタンスを受けとることができました。
DRbUnknownの機構によって、クラス定義を知らないオブジェクトを (メソッド呼び出しはできないが)保持しておくことが可能になります。
プロセス間でオブジェクトを交換するためのQueueを考えてみましょう。 中継するQueueのサービスがpushされる可能性のある全てのクラス定義を 事前に知らなくてはならないのは、難しいことがあります。 DRbUnknownはこういった局面で特に有用な機能です。
*1従来はDRbObject.new(nil, uri)のように生成しました